性能の高いAIが「教え下手」になる理由とは?AIエージェント学習の教育パラドックス
公開日
開発生産性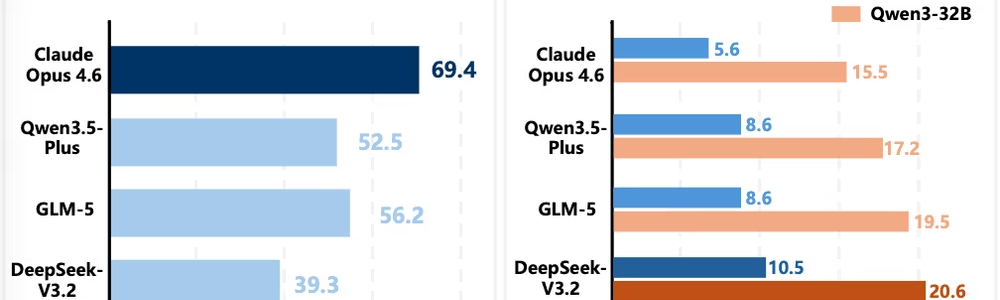
近年、開発環境と双方向に作用する自律的な「コーディングエージェント」の開発が活発化しています。これまでのモデル開発では、より強力なモデル(教師)から出力されたデータを、より小さなモデル(生徒)に学習させる「蒸留」という手法において、「強い教師ほど良い指導ができる」という前提が暗黙のうちに信じられてきました。
本記事では、香港大学、Huawei Technologies、南洋理工大学などの共同研究チームが発表した論文「What Makes Interaction Trajectories Effective for Training Terminal Agents?」(2026年)に基づき、この前提を覆す「指導力のパラドックス」の存在と、エージェントの指導力を左右する「環境接地型監視(EGS)」の有効性について解説します。
優秀なモデルが優れた教師になるとは限らない「指導力のパラドックス」
研究チームは、ターミナル環境でタスクを解くエージェントの性能について、教師モデル自身の正答率と、その実行ログ(軌跡)を学習した生徒モデルの性能を比較しました。その結果、非常に奇妙な現象が確認されました。
スタンドアロン性能と生徒モデルの成績の乖離
以下の図表1は、各教師モデル単体の正答率(①)と、それらのモデルが生成したデータでファイントゥーニングした生徒モデル(Qwen3-8BおよびQwen3-32B)の正答率(②)を示しています。
 図表1:スタンドアロン性能と指導力の乖離(指導力のパラドックス)
図表1:スタンドアロン性能と指導力の乖離(指導力のパラドックス)
単独の正答率([email protected])では、Claude Opus 4.6が69.4%と突出して高いスコアを記録しています。一方で、DeepSeek-V3.2のスコアは39.3%に留まります。
しかし、これらのモデルが生成したデータを生徒モデルに学習させたところ、最も優れた成績を収めたのはDeepSeek-V3.2のデータで学習した生徒モデルでした。Claude Opus 4.6のデータを学習した生徒モデルは、最も低い成績を示しています。
教師モデルの「効率性」と「指導力」の相反
この結果は、「タスクを解く能力」と「タスクの解き方を教える能力」が全く異なる次元であることを示しています。
高性能なモデルは、少ない手順で手際よく目的のコードを書き換える「ショートカット」を選択しがちです。しかし、その簡潔なプロセスは、思考の過程がログに現れにくいため、生徒モデルにとっては学習しづらいデータになります。対照的に、手順が多く慎重なプロセスのデータの方が、生徒にとって模倣しやすい教材となります。
検証の基盤となるタスク生成パイプライン「TERMINAL-LEGO」
本研究では、StackOverflowから収集された90以上の技術ドメインにわたる課題を、Dockerコンテナ上で実行検証可能なタスクに自動変換し、4種類の主要なLLMを用いて比較実験を行いました。
StackOverflowを起点とするタスク構築プロセス
検証の基盤となる「TERMINAL-LEGO」は、現実世界の多様なトラブルをエージェント用のタスクへ変換する仕組みです。具体的には、StackOverflowのQ&Aデータを収集し、LLMを用いて「課題指示書の作成」「実行環境の構築(Dockerfile)」「解決コード」「検証用テストコード」を段階的に生成します。生成されたタスクはすべてDockerコンテナ内で実際に実行され、正しく検証可能であること(ラウンドトリップ検証)が保証されています。
各教師モデルのデータと生徒モデルの成績
研究チームは、各教師モデルが共通して正解できた8.1K件のタスクを厳選し、生徒モデルを学習させました。
| 教師モデル | 軌跡データ数 | 教師単体のスコア (TB 2.0) | 平均実行ターン数 | 生徒:Qwen3-8B のスコア | 生徒:Qwen3-32B のスコア |
|---|---|---|---|---|---|
| Claude Opus 4.6 | 8.1K | 69.4% | 3.8 | 5.6% | 15.5% |
| Qwen3.5-Plus | 8.1K | 52.5% | 6.7 | 8.6% | 17.2% |
| GLM-5 | 8.1K | 56.2% | 5.4 | 8.6% | 19.5% |
| DeepSeek-V3.2 | 8.1K | 39.3% | 7.3 | 10.5% | 20.6% |
図表2:同じタスクセットを用いた教師・生徒モデルの性能比較
平均実行ターン数を見ると、Claude Opus 4.6は「3.8ターン」と極めて短い手数でスマートに解決していますが、生徒に与える学習効果は限定的です。一方、最も手数の多い「7.3ターン」を要したDeepSeek-V3.2が、生徒モデルの性能を最も引き出していることが確認できます。
鍵を握る「環境接地型監視(EGS)」と「標的観測比率(TOR)」
なぜ手数の多いモデルの方が、優れた教師になるのでしょうか。研究チームは、この原因が「環境接地型監視(EGS:Environment-Grounded Supervision)」にあると分析しています。
環境接地型監視(EGS)の概念
EGSとは、エージェントが「周囲の環境を確認(観測)し、その結果に基づいて行動し、さらにその結果が正しかったかを検証する」という、一連の丁寧な試行錯誤プロセスを指します。
ターミナル環境におけるEGSの具体的な行動には、以下のようなものが含まれます。
- 作業前に現在のフォルダ構成やファイルの記述内容を確認する(
lsやcatなど) - 編集後にファイルの内容が正しく書き換わったか再度確認する
- テストを実行してエラーメッセージの内容を精査する
行動の妥当性を測る「標的観測比率(TOR)」
研究チームは、EGSの度合いを定量的に測るための指標として、標的観測比率(TOR:Targeted Observation Ratio) を提案しました。これは、エージェントが実行した「変更を加えるコマンド(ファイル書き換えなど)」のうち、事前に「対象となるファイルやパスを適切に確認・観測していたコマンド」が占める割合を示します。
TORが高いデータ(軌跡)は、エージェントが当てずっぽうに行動しているのではなく、事前に状況を確認してから的確に編集を行っていることを示します。
| 観測カテゴリ | 代表的なコマンド | 露出する環境の状態 |
|---|---|---|
| 内容(Content) | cat, grep, head, wc, diff | ファイルの中身、出力、差分、データの正しさの証拠 |
| 構造(Structure) | ls, find, stat, file, which | ファイルパス、ディレクトリ構成、パーミッション |
図表3:ターミナルログにおける観測コマンドの分類
DeepSeek-V3.2は、単にファイルを書き換えるだけでなく、これらのコマンドを頻繁に用いて環境の状態を確認しながら処理を進めるため、TORが非常に高くなります。この「確認と行動のセット」が、生徒モデルにとって「なぜその操作を行うのか」を理解するための強力な学習シグナルとなります。
観測行動が学習効果に与える影響の検証
EGSおよびTORが本当に学習効果を高めているのかを検証するため、いくつかの追加実験が行われました。
観測コマンドのマスキングによる性能低下
研究チームは、最も学習効果の高かったDeepSeek-V3.2のデータから、観測に関連するコマンドとログ(cat や ls の実行部分など)を隠蔽(マスク)して生徒モデルに学習させました。
その結果、学習データから観測行動を除去すると、生徒モデルの正答率は20.6%から13.8%へと大幅に低下しました。これにより、生徒モデルが単に変更手順(コードの書き換え結果)だけを真似るのではなく、「事前確認を行う姿勢」そのものを学ぶことが極めて重要であることが実証されました。
失敗した軌跡から学習する生徒モデル
さらに驚くべきことに、最終的にタスクの解決に「失敗した」実行ログであっても、高いTORを持つ(手順が丁寧な)データであれば、生徒モデルを十分に賢くできることが分かりました。
2.5K件の「失敗したDeepSeek-V3.2のデータ」で学習したQwen3-32Bは、16.1%の正答率を達成しました。これは、8.1K件の「成功したClaude Opus 4.6のデータ」で学習したモデル(15.5%)を上回る結果です。正しい答えに至らなかったログであっても、「原因を調べ、実行し、確認する」という手続きが明瞭であれば、生徒にとっては価値のある教材になります。
既存システムとの比較評価
この環境接地型の丁寧なログを用いて15K件のデータで学習させた「Terminal-Lego-Qwen3-32B」は、従来のモデルと比較して極めて高いデータ効率を達成しています。
| モデル名 | パラメータ数 | 学習データ量 | 使用スクリプト | TB 2.0 スコア |
|---|---|---|---|---|
| Qwen 3 Coder 480B | 480B | - | Terminus-2 | 23.9% |
| GPT-5-Mini | - | - | Terminus-2 | 24.0% |
| Nemotron-Terminal-Qwen3-32B | 32B | 490.5K | Terminus-2 | 27.4% |
| Terminal-Lego-Qwen3-32B | 32B | 15.3K | Terminus-2 | 24.3% |
図表4:Terminal-Bench 2.0 における各種モデルのスコア比較
図表4に示す通り、数十万件規模の膨大なデータで学習した既存の高性能エージェント(Nemotron-Terminalなど)に迫る「24.3%」の正答率を、わずか15.3K件(約30分の1のデータ量)のファイントゥーニングで達成しました。
まとめと今後のエージェント開発における展望
本研究は、AIエージェントのポストトレーニングにおける新たな視点を提示しました。
これまで重視されてきた「最終的な出力の一致(Outcome-matching)」や「手数の短さ(効率性)」は、生徒モデルの学習においては必ずしも最適なデータにはなりません。エージェントを実用的なレベルへと訓練するためには、以下の点が重要になります。
- プロセスの可視化: 丁寧な確認と、行動に基づく結果検証のループ(EGS)が記録されていること。
- データ品質の定量化: TOR(標的観測比率)のような、行動と環境の接地性を測定する指標を用いてデータをフィルタリングすること。
- ハーネス設計の重要性: エージェントにただ結果を出させるだけでなく、環境との対話をログに残すような構造(Harness Engineering)を設計すること。
今後のエージェント開発においては、単に巨大なモデルを教師とするのではなく、環境と丁寧に対話するエージェントの挙動を意図的に作成し、それを学習データとして活用することが、効率的なエージェント構築の鍵となります。
生成AIの導入や活用にお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: