AIエージェントのセキュリティ、どう対応する? MAESTROフレームワーク解説
公開日
自律的にタスクを実行し、外部ツールと連携するAIエージェント(自律型AIエージェント)は、私たちの働き方やビジネスプロセスに革命をもたらす可能性を秘めています。しかし、その高度な能力と自律性は、従来のソフトウェアにはなかった新たなセキュリティリスクを生み出しており、既存の脅威モデリング手法だけでは十分に対応しきれない場面が増えています。
本記事では、このような課題に対応するため、Cloud Security Alliance (CSA) が発表した、AIエージェントに特化した脅威モデリングフレームワーク 「MAESTRO」 について、その基本原則、中核となる7層アーキテクチャを中心に詳しく解説します。さらに、MAESTROが実際にどのように活用できるかを理解するため、OpenAIの最新APIである「Responses API」を例とした具体的な分析も紹介します。
なぜAIエージェントには専用の脅威モデリングが必要なのか?
AIエージェントは、単に指示に従うだけでなく、自ら学習し、判断し、外部環境と相互作用しながら目標達成を目指します。このAIならではの特性が、従来のソフトウェアセキュリティの考え方だけでは捉えきれない、新たな課題を生んでいるのです。
限界が見えてきた? 従来の脅威モデリングフレームワーク
ソフトウェア開発の現場では、 STRIDE や PASTA といった脅威モデリングフレームワークが広く利用されてきました。これらは、なりすまし、改ざん、情報漏洩といった一般的なセキュリティリスクやプライバシーリスクを特定する上で非常に有効なツールです。
しかし、これらのフレームワークは、AI、特に自律的に動作するAIエージェントが持つ以下のようなユニークな特性を十分に考慮して設計されていません。
- 予測困難な振る舞い: AIエージェントの学習や意思決定プロセスは複雑で、時に開発者が予期しない結果や、望ましくない振る舞いを引き起こすことがあります。
- 機械学習モデル特有の脆弱性: AIの中核である機械学習モデル自体が攻撃対象となりえます。モデルを騙す入力(敵対的サンプル)、学習データへの悪意ある注入(データポイズニング)、モデル構造や学習データの窃取(モデル抽出)など、AI固有の攻撃手法が存在します。
- 複雑な相互作用: 複数のAIエージェントが連携したり、外部のAPIやツールと動的に連携したりするシステムでは、単体では見えなかった脆弱性やリスクが相互作用によって顕在化する可能性があります。
既存のフレームワークはAIエージェントの脅威の一部をカバーできますが、その全体像を体系的に把握し、効果的な対策を講じるには、AIの特性に合わせた新しいアプローチが必要なのです。
AIエージェントがもたらす新たなリスク
AIエージェント特有のリスクを理解することが、専用の脅威モデリングの必要性をさらに明確にします。主なリスク要因を見てみましょう。
- 自律性に関するリスク:
- エージェントの予測不可能性: 自ら判断し行動するため、その全ての振る舞いを事前に予測・制御することは困難です。意図しない有害なアクションにつながる可能性があります。
- 目標のずれ: 設定された目標が攻撃者によって悪用されたり、学習の過程で歪められたりすると、本来の目的から逸脱し、システムに損害を与える可能性があります。
- 機械学習特有のリスク:
- 敵対的機械学習: モデルの脆弱性を突き、誤認識や不正な出力を引き起こす攻撃(敵対的サンプル、データポイズニング、モデル抽出など)への対策が不可欠です。
- 堅牢性の欠如: 想定外のデータやノイズに対してモデルが脆弱な場合、システム全体の不安定化や予期せぬエラーを招くことがあります。
- 相互作用に関するリスク:
- エージェント間の相互作用: 複数のAIエージェントが連携する環境では、悪意のあるエージェントによる共謀や、競争関係の悪用といったリスクが生じます(例:市場価格操作)。
- システムレベルのリスク:
- 説明可能性と監査可能性の欠如: AIエージェントの判断根拠が不明瞭(ブラックボックス)だと、問題発生時の原因究明やコンプライアンス対応が困難になります。
- サプライチェーンセキュリティ: 外部のモデル、データ、ライブラリへの依存は、それらに脆弱性や悪意のあるコードが含まれていた場合、システム全体のリスクとなります。
これらのリスクは相互に関連しあい、複雑な脅威シナリオを生み出す可能性があります。だからこそ、AIエージェントのライフサイクル全体を見渡し、これらのリスクを体系的に評価できるフレームワークが求められているのです。
AIエージェント脅威モデリングの新基準:「MAESTRO」フレームワーク入門
このような背景から、AIエージェント特有の課題に対応するためにCSAのKen Huang氏によって提唱されたのが、 「MAESTRO(Multi-Agent Environment, Security, Threat, Risk, and Outcome)」 フレームワークです。MAESTROは、AIエージェントシステムのセキュリティを包括的に分析・評価するための新しい羅針盤となることを目指しています。
MAESTROとは? 5つの基本原則を解説
MAESTROは、AIエージェントの複雑な性質を捉えるために、以下の5つの基本原則に基づいています。
- 拡張されたセキュリティカテゴリ: STRIDEやPASTAなどの既存フレームワークの知見を活かしつつ、それらをAI特有の脅威(敵対的ML、自律性リスクなど)を考慮して拡張・補完します。AIの世界で新たに出現した脅威を見逃しません。
- マルチエージェントと環境へのフォーカス: 個々のAIエージェントだけでなく、それが動作する「環境」全体(他のエージェント、システム、データソース、人間との相互作用)を分析対象とします。AIエージェントは孤立して存在するわけではないという現実を反映しています。
- レイヤードセキュリティ(層状のセキュリティ): セキュリティを単一の対策レイヤーではなく、AIエージェントシステムのアーキテクチャ全体、基盤モデルから最終的なエコシステムに至るまでの「各層」に組み込まれるべき横断的な特性として捉えます。
- AI特化の脅威への対応: 敵対的機械学習、目標のずれ、自律性に伴う予測不可能性など、AI技術に固有の脅威とその影響を正面から評価します。
- リスクベースアプローチと継続的な監視・適応: 全ての脅威に等しく対応するのではなく、発生可能性と潜在的な影響度に基づいてリスクを評価し、優先順位をつけて対策を講じます。また、AIと脅威は常に進化するため、継続的な監視と脅威モデルの適応(アップデート)を重視します。
MAESTROの中核:7層参照アーキテクチャを理解する
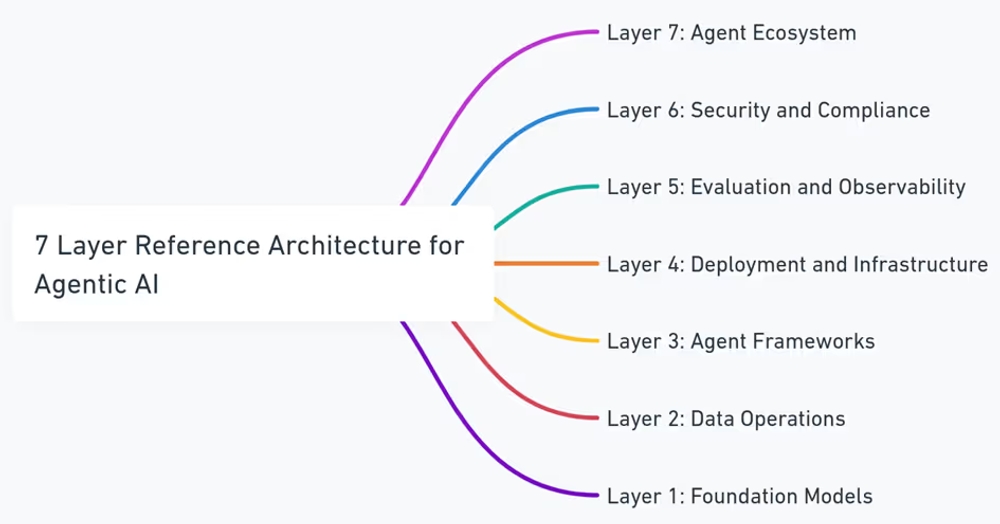
MAESTROフレームワークの最も特徴的な点は、複雑になりがちなAIエージェントのエコシステムを、機能的に区別される 7つの層(レイヤー) に分解して分析するアプローチを採用していることです。これにより、どこにどのようなリスクが潜んでいるのかを構造的に理解しやすくなります。
MAESTRO 7層参照アーキテクチャ
MAESTROの7層の概要:
- Layer 1: Foundation Models (基盤モデル): AIエージェントの「頭脳」にあたる中核的なAIモデル(例: GPT-4oのようなLLM)。モデル自体の脆弱性や信頼性が問われます。
- Layer 2: Data Operations (データ操作): エージェントが学習や推論に使用するデータの流れ全体。データの収集、処理、保存、検索(例: RAGで使うベクトルストア)など、データの品質とセキュリティが焦点です。
- Layer 3: Agent Frameworks (エージェントフレームワーク): AIエージェントを構築し、その動作(ツール連携、対話管理など)を支えるソフトウェアライブラリやAPI(例: LangChain, OpenAI Responses API)。フレームワーク自体の安全性や、それを利用する際のリスクを評価します。
- Layer 4: Deployment and Infrastructure (デプロイとインフラ): AIエージェントが実際に稼働する環境。クラウドプラットフォーム、サーバー、コンテナ、ネットワークなど、実行基盤のセキュリティが対象です。
- Layer 5: Evaluation and Observability (評価と可観測性): AIエージェントの性能を評価し、その動作を監視・追跡するための仕組み。評価指標の信頼性や、監視データの保護、異常検知能力などが重要になります。
- Layer 6: Security and Compliance (セキュリティとコンプライアンス): システム全体に適用されるべきセキュリティポリシー、アクセス制御、暗号化、法規制遵守(例: GDPR)などの横断的な要件を扱います。
- Layer 7: Agent Ecosystem (エージェントエコシステム): 開発したAIエージェントが、他のエージェントや外部システム、ユーザーと相互作用する最終的な「社会」や「市場」。エージェント間の信頼関係や予期せぬ相互作用によるリスクを評価します。
この7層モデルを用いることで、AIエージェントシステムのどの部分に注力して脅威分析を行うべきか、また、各層がどのように相互に影響し合うのか(クロスレイヤー脅威)を体系的に把握し、漏れのない対策を検討することが可能になります。
なぜMAESTROを使うべきか? そのメリット
MAESTROフレームワークを採用することには、以下のようなメリットがあります。
- AI特化のリスクへの対応: 既存手法では見落としがちなAI固有の脅威(敵対的攻撃、自律性リスクなど)を体系的に評価できます。
- 包括的な分析: 7層アーキテクチャにより、AIエージェントシステム全体を構成要素レベルからエコシステムレベルまで、多角的に分析できます。
- 構造化されたアプローチ: 脅威の特定、リスク評価、対策立案のプロセスを構造化し、効率的かつ網羅的な脅威モデリングを支援します。
- 共通言語の提供: 開発者、セキュリティ担当者、研究者などがAIエージェントのセキュリティについて議論するための共通の枠組みと語彙を提供します。
- プロアクティブな対策: 開発の初期段階から脅威を特定し、設計にセキュリティを組み込む「セキュリティ・バイ・デザイン」を促進します。
MAESTRO実践:OpenAI Responses API をケーススタディに
理論だけではイメージしにくいかもしれませんので、MAESTROフレームワークが実際のAI開発でどのように活用できるか、具体的なケーススタディとしてOpenAIの「 Responses API 」を用いた脅威分析の概要を見ていきましょう。これは、MAESTROの考え方を適用することで、特定の技術に対してどのようなリスクが浮かび上がってくるかを示す一例です。
ケーススタディの対象:OpenAI Responses API とは?
OpenAI Responses APIは、単なるテキスト生成APIではなく、AIエージェントの構築を強力に支援する機能群を提供します。特に「オーケストレーション」、つまり一連の対話、ツール呼び出し、モデル応答を管理・調整する能力に優れています。
- ステートフルな会話: 過去の対話履歴を保持し、文脈に基づいた応答やタスク実行が可能です。
- ツール連携: Web検索やファイル検索などの組み込みツール、そして開発者が独自に定義できるカスタムツール(関数呼び出し)との連携が可能です。
- 構造化出力: JSON形式での出力を指定でき、プログラムでの扱いを容易にします。
これらの機能はAIエージェント開発を加速しますが、同時にMAESTROの各層に関連する新たなセキュリティリスクも内包しています。
Responses API の脅威分析概要
MAESTROの7層モデルに対して、Responses APIの各層で考えられる主な脅威と対策の方向性を整理すると以下のようになります。
各レイヤーにおける脅威と対策の方向性:
- Layer 1 (基盤モデル):
- 脅威例: 敵対的サンプル、データポイズニング、モデル抽出、プロンプトインジェクション(モデル自体を騙す)
- 対策の方向性: 入力・出力検証、堅牢なプロンプト設計、レート制限、異常検知
- Layer 2 (データ操作):
- 脅威例: RAG等で利用するベクトルストア/ファイルへのデータ汚染、データ漏洩、不正確/古いデータ利用
- 対策の方向性: アクセス制御、データ整合性検証、暗号化、監査、データ更新
- Layer 3 (エージェントフレームワーク):
- 脅威例: ツール(関数)の不正利用、プロンプトインジェクション(APIへの指示を乗っ取る)、リソース過剰消費
- 対策の方向性: ツール引数の厳格な検証、入出力サニタイズ、最小権限、レート制限/ループ検出
- Layer 4 (インフラ):
- 脅威例: DoS/DDoS攻撃、インフラ侵害(主にOpenAI側の責務)
- 対策の方向性: (ユーザー側) ステータス監視、リトライ/フォールバック戦略、SLA確認
- Layer 5 (評価と可観測性):
- 脅威例: 評価指標の操作、監視回避、ログからの情報漏洩
- 対策の方向性: 安全なログ/監視設定、アクセス制御、異常検知、データ最小化
- Layer 6 (セキュリティとコンプライアンス):
- 脅威例: 不正APIアクセス(キー漏洩)、レート制限回避、プライバシー規制違反
- 対策の方向性: 安全なAPIキー管理、キーローテーション、最小権限、データ最小化/匿名化
- Layer 7 (エージェントエコシステム):
- 脅威例: 悪意のあるエージェント間相互作用、共謀、誤情報拡散
- 対策の方向性: 安全なエージェント間通信、評判システム、サンドボックス化、相互作用監視
- クロスレイヤー脅威: 単一レイヤーの脆弱性が他のレイヤーに波及する脅威(例: Layer 3のプロンプトインジェクションがLayer 4のインフラ侵害につながる可能性)にも注意が必要です。
このようにMAESTROを適用することで、OpenAI Responses APIのような特定の技術に対しても、多層的かつ体系的にリスクを洗い出し、具体的な対策の方向性を見出すことができます。
まとめ:MAESTROを羅針盤に、安全なAIエージェント開発の航海へ
AIエージェント技術は目覚ましい進化を遂げ、OpenAI Responses APIのような強力なツールが登場しています。これらの技術は大きな可能性を秘めていますが、同時に新たなセキュリティ上の課題も突きつけています。
本記事で詳しく解説したMAESTROフレームワークは、AIエージェント特有の複雑なリスクを理解し、それらに立ち向かうための強力な羅針盤となります。その7層アーキテクチャに基づいた体系的なアプローチは、開発者やセキュリティ担当者が潜在的な脆弱性を多角的に洗い出し、効果的な対策を講じる上で大きな助けとなるでしょう。
AIエージェントのセキュリティを確保するためには、以下の点を心に留めておくことが重要です。
- セキュリティは継続的なプロセス: 脅威モデリングは一度行えば終わりではありません。AI技術や脅威環境は常に変化するため、継続的な見直しと更新が不可欠です。
- 多層防御が不可欠: 単一の対策に依存せず、MAESTROの各レイヤーにわたる複数のセキュリティ制御を組み合わせることが、堅牢な防御体制を築く鍵となります。
- コンテキストが重要: 開発するアプリケーションの特性や運用環境に応じて、リスクの優先順位や最適な対策は異なります。状況に合わせた判断が求められます。
セキュリティを開発プロセスの中核に据え、MAESTROのようなフレームワークを活用することで、私たちはAIエージェントの持つ力を、安全かつ責任ある方法で最大限に引き出すことができます。本記事が、皆様の安全なAIエージェント開発の一助となれば幸いです。
Webサービスや社内のセキュリティにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: