開発時にAI生成コードの申告はするべき?開発者アンケート結果
公開日
AIによるコード生成が、ソフトウェア開発の現場で急速に身近なものになってきました。GitHub CopilotやChatGPTのようなツールは、開発の生産性を飛躍的に向上させる可能性を秘めていますが、同時に新たな課題も生んでいます。その一つが、「AIが生成したコード(AI生成コード)をどのように扱い、その出自をどう示すか」という問題です。AI生成コードを人間が書いたコードと区別し、その旨を明示する「自己申告」は、なぜ重要なのでしょうか?
本記事では、Syed Mohammad Kashif氏らによる研究論文「On Developers’ Self-Declaration of AI-Generated Code: An Analysis of Practices」(2025年)で明らかにされた、開発者の「AI生成コード自己申告」に関する最新の調査結果に基づき、その重要性、現場でのリアルな実践状況、そして私たちがAIとより良く協調していくための具体的なガイドラインを分かりやすく解説していきます。
なぜAI生成コードの「自己申告」は重要なのか?
AIが生成したコードを人間が書いたコードと区別し、その旨を「自己申告」することは、一見すると手間が増えるだけの作業に思えるかもしれません。しかし、この研究では、自己申告が開発プロセスにおいて非常に重要な役割を果たすことが示唆されています。主な理由として、以下の3点が挙げられます。
1. 追跡可能性とデバッグ効率の向上
AI生成コードは、時に予期せぬバグを含んでいたり、特定の状況下で意図しない動作をしたりする可能性があります。コードのどの部分がAIによって生成されたのかを明確にしておくことで、将来的なバグ修正や機能改修の際に、問題箇所を特定しやすくなります。多くの開発者が、将来のコードレビューやデバッグのためにAI生成コードを追跡・監視する必要性を感じていることが、本研究の調査でも明らかになっています。これは、コードの保守性を高め、開発効率の低下を防ぐ上で不可欠です。
2. 倫理的配慮と透明性の確保
AI生成コードの利用には、著作権や責任の所在といった倫理的な側面が伴います。コードの出自を明確にすることで、開発チーム内や関係者間での透明性を高め、AIの利用に関する責任ある姿勢を示すことができます。特に、AIが生成したコードが何らかの問題を引き起こした場合、その原因究明や対策を講じる上で、生成元がAIであることを把握しておくことは極めて重要です。
3. コード品質の担保と継続的改善
AI生成コードは万能ではなく、必ずしも最適な品質であるとは限りません。自己申告を通じて、AI生成コードであることをチームメンバーが認識することで、より慎重なコードレビューやテストが行われるきっかけになります。また、AI生成コードの品質に関するフィードバック(例:「この部分はAIが生成したが、テストの結果問題なかった」「AIの提案はAだったが、Bのように修正した」など)をコメントとして残すことは、チーム全体の知見となり、将来のAI活用やコード品質の改善に繋がります。
AI生成コード「自己申告」のリアル:開発現場の実態調査
では、実際の開発現場では、AI生成コードの自己申告はどの程度行われ、どのような方法が取られているのでしょうか?この研究では、開発者へのアンケート調査とGitHubリポジトリの分析という2つのアプローチから、その実態に迫っています。
【アンケート調査結果】開発者はAIコードをどう思っている?
この調査では、AIコード生成ツールを業務で使用する世界26カ国のソフトウェアエンジニアを中心に募集し、スクリーニングを経た111人から有効な回答を得ています。
自己申告の頻度:「いつも」「時々」「全くしない」の割合は?
大多数の開発者がAI生成コードを何らかの形で自己申告していることが明らかになりました。調査によると、76.6%の開発者が「常に」または「時々」AI生成コードを自己申告しており、「全く申告しない」と回答した開発者は23.4%に留まりました。これは、多くの開発者が自己申告の必要性を認識していることを示唆しています。
自己申告する理由:開発者の本音
開発者がAI生成コードを自己申告する主な理由として、アンケートからは以下のような声が寄せられました。下の表は、その主な理由をまとめたものです。
| カテゴリ | 「AI生成コードを自己申告する理由」への回答 | 回答数 (%) |
|---|---|---|
| 将来のレビューとデバッグのための追跡と監視 | 開発者は、AI生成コードがプロジェクトのどこで使用されているかを追跡するために自己申告コメントを使用します。これにより、将来の参照、品質チェック、デバッグ、改善に役立ちます。 | 28 (25.2%) |
| 透明性、説明責任、および倫理的配慮 | 開発者は、倫理的な理由から、また開発プロセスにおける透明性と説明責任を維持するために、AI生成コードの出自を明確に述べることで自己申告します。 | 23 (20.7%) |
| コード品質の評価と改善 | 開発者は、コードの品質を説明するAI生成コードを自己申告します。これはコードの信頼性を示し、将来のコード改善に役立ち、それによってコードの可読性を向上させます。 | 15 (13.5%) |
| チーム内での知識共有 | 開発者は、プロジェクトに統合されたコードのコンテキストを提供するためにAI生成コードを自己申告します。これにより、チーム内での開発に関する知識共有が促進され、コラボレーションが容易になります。 | 10 (9%) |
最も多かったのは「将来のレビューやデバッグのための追跡・監視」(25.2%) で、次いで「透明性、説明責任、倫理的配慮」(20.7%) となっています。
自己申告しない理由:その背景とは
一方で、自己申告しない開発者にも様々な理由があります。主なものとしては、「AI生成コードに大幅な修正を加えているため、もはや自分のコードだと感じる」(11.7%)、「自己申告は不要な作業であり、オンラインドキュメントを参照するのと同様だと感じる」(11.7%) といった意見が挙げられました。詳細は以下の表の通りです。
| カテゴリ | 「AI生成コードを自己申告しない理由」への回答 | 回答数 (%) |
|---|---|---|
| カスタマイズと修正 | AI生成コードには欠陥があり、ビジネス要件を満たさないため、開発者は自己申告しません。彼らはプロジェクトに追加する前に徹底的にレビュー、変更、テストを行い、それが彼ら自身の貢献となります。 | 13 (11.7%) |
| 自己申告は不要 | 開発者は、生産性を向上させるためにAIコード生成ツールを使用しますが、開発において完全にそれらに依存しているわけではないため、自己申告しません。彼らは、オンラインドキュメントやディスカッションフォーラム(Stack Overflow)で助けを求めるのと同様だと考え、自己申告する必要性を感じません。 | 13 (11.7%) |
| その他の理由 | 開発者は、怠慢、組織からの適切な要件の欠如、または時にはAI生成コードに関するセキュリティや正当性の懸念による組織からの非推奨など、あまり一般的でない理由も共有しました。 | 6 (5.4%) |
【GitHubリポジトリ分析】AIコードはどうコメントされている?
研究チームはさらに、特定のキーワードで検索し、AIによる生成が自己申告されている公開GitHubリポジトリから、一定の基準(言語の多様性、プロジェクト規模など)でフィルタリングした613のAI生成コードスニペットを収集し、開発者が実際にどのように自己申告コメントを記述しているかを分析しました。
コメント内容の傾向:開発者が伝える情報とは?
自己申告コメントには、単に「AIが生成した」と述べるだけでなく、様々な情報が含まれていました。主なパターンは以下の通りです。
| カテゴリ | 自己申告コメントの例 | 回答数 (%) |
|---|---|---|
| シンプルな自己申告 | 1. この関数は主にCopilotによって書かれました ( コメントへのリンク ) 2. Kristin WitteとGitHub Copilot (そしてChatGPT) によってコーディングされました ( コメントへのリンク ) 3. 注意:AI生成関数 ( コメントへのリンク ) | 214 (34.9%) |
| コードの説明 | 4. Copilotによって書かれた、色の薄い陰影を作成する関数 ( コメントへのリンク ) 5. ChatGPTによる、指定された要素を除くページ全体をグレースケール化するソリューション ( コメントへのリンク ) | 185 (30.0%) |
| 文脈情報 | 6. ChatGPTのおかげで書かれた関数 ( ChatGPTの会話リンク ) ( コメントへのリンク ) 7. Brian Birdによって2024年4月9日にGitHub Copilotの支援を受けて書かれました ( コメントへのリンク ) | 209 (34.0%) |
| コード品質に関する注記 | 8. プレイヤークラスは完全に人間によって書かれ、Copilotの支援を受けています (75%人間、25%AI) ( コメントへのリンク ) 9. 注意:(2023年11月24日) このコードのほとんどはChatGPT (GPT-4) によって生成されました。これは迅速な解決策であり、改良が必要です ( コメントへのリンク ) | 110 (18.0%) |
最も多かったのは「シンプルな自己申告」(34.9%) ですが、「文脈情報」(34.0%) や「コードの説明」(30.0%) も多く見られました。
コメントの範囲:「ファイル全体」か「コードの一部」か
自己申告コメントが適用される範囲も様々です。
-
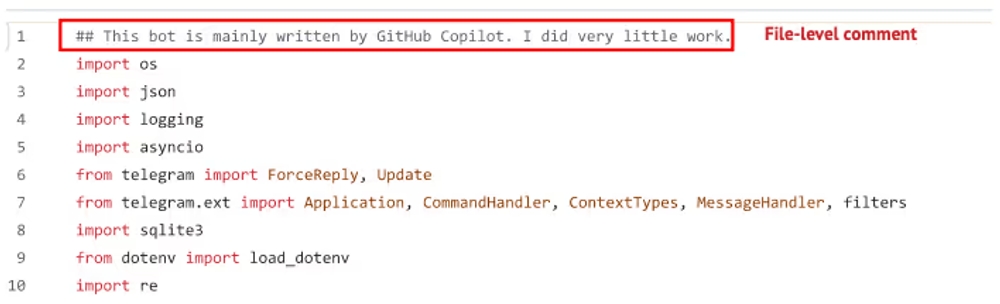
ファイルレベルでの申告:ファイルの冒頭などで「このファイルは主にAIによって生成されました」といったコメントが見られました。これは、ファイル全体がAIの支援を大きく受けている場合に用いられる傾向があります。
-
スニペット(一部分)レベルでの申告:特定の関数やクラスの直前にコメントを付与し、その部分のみがAI生成であることを示すケースです。こちらの方がより一般的で、収集されたコメントの約7割を占めていました。
AIで生成されやすいコード:言語と分野の傾向
収集されたAI生成コードスニペットを分析した結果、プログラミング言語ではJavaScriptとPythonが多く、アプリケーションドメインではWebアプリケーションが最も多いことが分かりました。これは、これらの分野でAIコード生成ツールの活用が進んでいることを示唆しています。
開発者の満足度:AI生成コードは好評?
自己申告コメントの中には、AI生成コードに対する開発者の感情が表れているものもありました。全体的には、AIツールの有用性を認めるポジティブなコメントが多いものの(約85%)、生成されたコードの品質に対する不満や改善の必要性を示すネガティブなコメントも見られました。
AI生成コード「自己申告」の実践ガイドライン
これらの調査結果を踏まえ、研究ではAI生成コードを効果的に自己申告するためのガイドラインが提案されています。明日からの開発に役立つポイントを以下にまとめました。
1. 基本:正直に、分かりやすく申告する
AIによってコードを生成した場合は、その事実を隠さずに正直に申告することが基本です。特に、十分にテストされていないコードや、自分自身が完全に理解していないコードについては、積極的に申告し、チームメンバーに注意を促しましょう。
2. 情報:ツール名、箇所、生成コンテキスト(プロンプト等)を明記
「AIが生成した」というだけでなく、どのAIツール(例:ChatGPT、GitHub Copilot)を使用したのか、コードのどの部分(関数名、クラス名など)が該当するのかを具体的に記述します。可能であれば、どのような指示(プロンプト)でコードを生成したのかを記録しておくと、後からコードの意図を理解するのに役立ち、再現性も高まります。
3. 説明:複雑なコードには機能や目的を追記
AIが生成したコードが複雑であったり、自明でなかったりする場合には、そのコードが何をするのか、なぜ追加されたのかといった簡単な説明をコメントとして加えることが推奨されます。これにより、他の開発者がコードを理解しやすくなり、レビューやメンテナンスの効率が向上します。
4. 品質:テスト状況や修正箇所も共有
生成されたコードに対して、テストを実施したか、人間がどの程度修正を加えたか、既知の問題点や限界はあるかといった品質に関する情報も共有しましょう。「テスト済みで問題なし」「一部手動でバグ修正」「〇〇のケースでは動作しない可能性あり」といった具体的な情報は、コードの信頼性を判断する上で非常に有益です。
5. 範囲:管理しやすさを考え、ファイル単位かスニペット単位かを選択
コード全体がAIによって大きく支援されている場合は、ファイルの先頭にまとめて申告(ファイルレベル)するのも一つの方法です。しかし、より正確なトレーサビリティを確保するためには、 AIが生成した特定のコードブロック(関数、クラスなど)の直前にコメントを記述する(スニペットレベル) ことが推奨されます。どちらが良いかは、プロジェクトの状況やチームの方針に応じて判断しましょう。
まとめ:AIとの協調時代における「自己申告」の価値
AIによるコード生成は、もはや開発現場から切り離せない技術となりつつあります。本記事で紹介した調査結果は、多くの開発者がAI生成コードの「自己申告」の重要性を認識し、様々な形で実践していることを示しています。
AI生成コードの出自を明確にすることは、コードの追跡可能性を高め、倫理的な配慮を促し、そして最終的にはコード全体の品質向上に繋がります。今回提案されたガイドラインを参考に、皆さんの開発現場でもAIとのより良い協調関係を築き、質の高いソフトウェア開発を目指してみてはいかがでしょうか。将来的には、AIコード生成ツール自体に、このような自己申告を支援する機能が組み込まれることも期待されます。
開発生産性やチームビルディングにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: