Googleのコード移行戦略:AI活用で効率化 - 50%以上の時間削減を実現
公開日
近年、多くの企業がレガシーシステムのモダナイゼーションの一環としてコード移行に取り組んでいます。しかし、特に大規模なコードベースを持つ企業にとって、コード移行は膨大な時間と労力を要する複雑な作業であり、大きな負担となっています。この課題を解決する可能性を秘めているのが、近年目覚ましい発展を遂げているAI、特に大規模言語モデル(LLM)です。LLMの自然言語理解・生成能力をコード移行に応用することで、作業の自動化・効率化が期待できます。
本記事では、Googleが社内のコード移行にどのようにAIを活用しているのか、その具体的な事例と効果、今後の展望について、2025年1月に発表された論文「How is Google using AI for internal code migrations?」(Nikolov et al., 2025)を基に解説します。Googleにおけるコード移行の取り組みは、レガシーシステムを抱える多くの企業にとって参考になるでしょう。
Googleにおける一般的なAIツールの活用
Googleでは、コード補完をはじめとする、様々な開発支援ツールにLLMが活用されています。これらのツールは、開発者の生産性向上に大きく貢献しています。
開発支援ツールにおけるLLMの活用
Googleは、社内開発者向けに、LLMを活用した様々な開発支援ツールを提供しています。これらのツールは、コードの記述、レビュー、デバッグなど、開発プロセスの様々な場面で活用されています。特に、IDE(統合開発環境)内で動作するコード補完ツールは、多くの開発者に利用されています。
以下の図は、コーディングツールにおけるAIベースの機能の改善サイクルを示しています。ユーザーの操作ログは、機能の改善に役立てられ、また、ソフトウェア開発のためのAIモデルをトレーニングするためにも使用されています。
AIによるコード補完の効果:具体的な数値データ
Googleの社内調査によると、AIによるコード補完の受け入れ率は38%に達しています。これは、開発者がAIの提案を積極的に活用していることを示しています。さらに、AIは実際のコードの67%を生成しており、開発者のコーディング作業を大幅に効率化していることが分かります。
IDEにおけるAIによるコード補完、コピー&ペースト調整、自然言語によるコード編集の例
これらの数値は、AIが開発者の生産性向上に大きく貢献していることを示しています。
特注ソリューションとしてのLLM活用 - コード移行への適用
Googleでは、一般的な開発支援ツールに加えて、特定の課題を解決するための「特注」ソリューションにもLLMを活用しています。コード移行は、その代表的な例です。
一般的なツールとの違い
一般的な開発支援ツールは、多くの開発者に共通するニーズを満たすように設計されています。一方、特注ソリューションは、特定の課題やユースケースに特化して開発されます。コード移行は、企業やプロジェクトによって要件が大きく異なるため、特注ソリューションが適しています。
LLMを用いたコード移行の課題とアプローチ
LLMをコード移行に活用する際には、いくつかの課題があります。例えば、LLMは、コードの構文や意味を完全に理解しているわけではありません。また、移行先の仕様や要件を正確に把握することも困難です。
Googleでは、これらの課題に対処するために、LLMと他の技術を組み合わせたアプローチを採用しています。具体的には、LLMはコードの編集生成に焦点を当て、変更箇所の特定や検証は主に決定論的AST(抽象構文木)技術によってサポートしています。
AIによるコード変更を大規模リポジトリに適用するまでのプロセス概要

成功の指標:タスク完了率の向上
Googleでは、LLMを用いたコード移行の成功を測る指標として、タスク完了率の向上を重視しています。具体的には、AI支援によって、進行中のプロジェクトのタスク完了率が少なくとも50%向上することを目指しています。
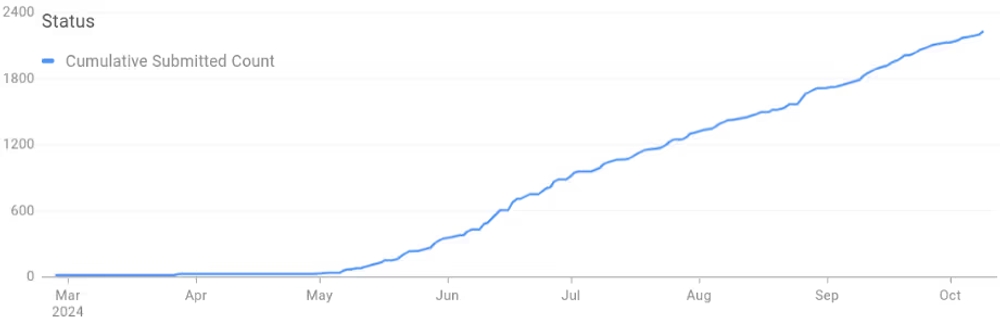
以下の図は、AI支援による移行の最初の3四半期の提出済み変更リストの推移を示しています。これを見ると、AIを活用したコード移行が活発に行われていることがわかります。
事例紹介 - Googleにおける具体的なコード移行プロジェクト
本セクションでは、GoogleにおけるLLMを用いたコード移行の具体的な事例を4つ紹介します。
事例1:Int32からInt64へのID移行 (Google Ads) - 50%の時間削減
移行の背景と課題
Google Adsでは、ユーザー、広告主、キャンペーンなどを識別するために、数十種類の固有の「ID」が使用されていました。これらのIDは、当初32ビットの整数型(Int32)で定義されていましたが、ビジネスの成長に伴い、近い将来32ビットの範囲を超える可能性が出てきました。そのため、64ビットの整数型(Int64)への移行が必要となりました。
この移行には、以下のような課題がありました。
- IDは多くの場合、int32_t(C++)やInteger(Java)などの一般的な数値型として定義されており、簡単には検索できない型のため、特定が困難
- IDは数千ファイル、数万箇所のコードで使用されている
- 関連するすべてのチームが個別に移行作業を行うと、膨大な調整コストが発生する
- クラスのインターフェース変更は、複数のファイルに影響を及ぼす
- テストの更新が必要
- C++マクロとして表現される定数、テキストとしてシリアライズされるIDなどへの対応
LLMを用いた移行プロセス
Googleでは、この移行を効率化するために、LLMを用いた特注ソリューションを開発しました。移行プロセスは、以下のように進められました。
- 移行対象の特定: 専門のエンジニアが、移行対象のIDを特定し、Code Search、 Kythe 、カスタムスクリプトを用いて、影響を受ける可能性のあるファイルと場所を特定しました。
- コード変更の生成: LLMベースの移行ツールを用いて、コード変更を自動生成しました。このツールは、単体テストをパスする、検証済みの変更のみを生成します。必要に応じて、テストも更新されます。
- 手動レビューと修正: エンジニアが、生成された変更を手動でレビューし、必要に応じて修正しました。
- 変更の適用: 変更は細分化され、コードベースの所有者にレビューのために送信されました。
Int32からInt64へのID移行における、LLMを用いたマルチステージコード移行プロセスの実行例
以下は、この移行で実際に使用されたLLMへのプロンプト例です。
{id} should be of type int64_t.
Update the tests to reflect a large id.
Initialize the {id}s with values larger than 10000000000.
If necessary add new test parameters with large ids.
If previous id was negative, new value should be negative.
移行結果と効果
この移行プロジェクトにおいて、生成された変更の80%がAIによって完全に自動生成され、残りの20%がAIの提案を基に人間が修正・作成したものでした。結果として、移行にかかる時間は、LLMを使用しない場合と比較して推定50%削減されました。
事例2:JUnit3からJUnit4への移行 - 87%のコードを自動生成
移行の背景と課題
Googleのコードベースの一部では、古いテストフレームワークであるJUnit3が使用されていました。JUnit4への移行は、テストの保守性や拡張性を向上させるために必要でしたが、以下のような課題がありました。
- 手動での移行は膨大な時間と労力を要する
- 古いテストは開発のクリティカルパス上にはないが、コードベースに悪影響を及ぼす
- 開発者が誤って古いコードをコピーして新しいテストを作成する可能性がある
- 純粋なASTベースの手法では対応が難しいエッジケースが多数存在する
LLMを用いた移行プロセス
Googleでは、LLMを用いてJUnit3からJUnit4への移行を自動化しました。移行プロセスは、以下の通りです。
- 移行対象の特定: リポジトリ内のすべてのJUnit3テストがリストアップされました。
- コード変更の生成: LLMベースの移行ツールを用いて、コード変更を自動生成しました。このツールは、Googleの内部コードベースでファインチューニングされたGeminiモデルを活用しています。
- 変更のレビュー: 生成された変更は、Large Scale Changes システム(大規模なコード変更を適切なレビュアーに割り当てるGoogleの社内システム)によって自動的に細分化され、テストの所有者にレビューのために送信されました。
以下は、この移行で実際に使用されたLLMへのプロンプト例です。
You are a frontend software engineer that is an expert at Java, JUnit3, and JUnit4. Your work involves upgrading Java unit test files from JUnit3 to JUnit4. Convert all provided test files below from JUnit3 to JUnit4. Add imports for all the assert methods used in this file.
Here are some tips to keep in mind:
Steps:
1. Change the imports
* Remove imports for anything under ‘junit.framework‘ or ‘junit.extensions‘
* Add ‘import static org.junit.Assert.*‘
2. Remove the base class from the test. JUnit4-style tests should not extend ‘junit.framework.TestCase‘
3. It is rarely necessary to have a base class for JUnit4-style tests. Often you can write custom rules to share code
4. Annotate the test class with ‘@RunWith(JUnit4.class)‘
5. Annotate the test methods with ‘@Test‘
...
移行結果と効果
この移行プロジェクトでは、5,359ファイル、149,000行以上のコードが、3ヶ月で移行されました。AIによって生成されたコードの約87%が、最終的に変更なしでコミットされました。
事例3:Joda TimeからJava Timeへの移行 - 89%の時間削減
移行の背景と課題
Googleのコードベースの一部では、日時処理ライブラリとしてJoda Timeが使用されていました。標準の java.time パッケージへの移行が必要でしたが、以下のような課題がありました。
- 変更は単一のメソッドに限定されず、多くの場合、クラスのパブリックインターフェースやフィールドの変更が必要
- 一度にすべての出現箇所を更新できないため、作業を分割して個別にレビュー・コミットする必要がある
- 変更をレビューできるコードレビュー担当者の継続的な確保が難しい場合がある
- 移行対象のコンポーネントとそれ以外のコンポーネント間の依存関係により、型変換のためのラッパー関数が必要になる
- 型が1:1で対応していないケースがある(例:
joda.time.Intervalとjava.time.Duration)
LLMを用いた移行プロセス
Googleでは、LLMを用いてJoda TimeからJava Timeへの移行を段階的に進めました。移行プロセスは、以下のように進められました。
- 変更対象の特定: レビュアーが対応可能なディレクトリから開始し、Kytheを用いてJoda Timeの型が使用されている箇所と依存関係を特定しました。
- コールグラフの構築: 移行対象ファイルの依存関係を分析し、コールグラフを構築しました。
- 変更のクラスタリング: 変更を、インターフェースの変更が不要なもの、影響を受けるファイル数に基づくもの、依存関係の「エスケープ」の有無に基づくものなどに分類しました。
- コード変更の生成: LLMを用いて、コード変更を自動生成しました。依存関係がある場合は、すべてのファイルを一度にプロンプトに含め、一貫性を確保しました。
- 変更のレビュー: 生成された変更は、コードレビュー担当者によってレビューされました。
以下は、この移行で実際に使用されたLLMへのプロンプト例です。
Remove the usage of the joda.time classes and instead use the standard java.time module.
Update all usages of the Joda classes with their standard counterparts. Import the correct java.time module classes if needed.
Additional instructions:
* Instant is a drop-in replacement. So if you see joda.time.Instant, you can easily just replace it with a java.time.Instant.
* When you see something like new Instant(Long.MAX_VALUE), that is just java.time.Instant.MAX
* \new Instant(0)" on the other hand is just java.time.Instant.EPOCH
* joda.time.Instant’s ctor’s replacement is java.time.Instant.ofEpochMilli
* joda.time.Instant.getMillis() maps to java.time.Instant.toEpochMilli()
* Don’t use Instant.now() instead use Timesource.system().now()
* joda.time.Duration can be replaced with java.time.Duration.
* Instead of joda.time.Duration.millis(), call java.time.Duration.ofMillis()
* Instead of joda.time.Duration.getMillis() call java.time.Duration.toMillis()
* Instead of joda.time.Duration.standardSeconds() call java.time.Duration.ofSeconds()
* Instead of joda.time.Duration.standardMinutes() call java.time.Duration.ofMinutes()
* Prefer to use Instant over DateTime unless you really need to print out or manipulate Dates vs a specific point in time (eg Instant)
* If you really need joda.time.DateTime, use java.time.ZonedDateTime as a replacement
* Don’t use common.time.Clock. Use common.time.TimeSource instead
* Interval is NOT a drop in replacement so be very careful
* joda.time.Interval can be carefully replaced by common.collect.Range<java.time.Instant>
* Caveat, joda.time.Interval is closed-open so when creating the Range<Instant> and you want 100% compatibility, you need a closed-open Range.
Never rename functions or completely remove their implementation.
移行結果と効果
この移行プロジェクトでは、小さなクラスタにおいて、人間が手動で変更した場合と比較して、約89%の時間を削減できると推定されています。
事例4:実験用フラグのクリーンアップ - 不要なコードを自動削除
クリーンアップの背景と課題
Googleでは、新機能のテストや効果測定のために、数千ものランタイム実験が常時実行されています。実験が終了した後、関連するコードはクリーンアップされる必要がありますが、以下のような課題がありました。
- 実験用フラグは、デフォルトのコードパスになるか、完全に削除される必要がある
- 多数の実験が放置され、コードベースに悪影響を及ぼす
- 値が長期間変更されていない「古くなった」フラグが存在する
- 開発者は、関連するコードを手動でクリーンアップする必要がある
LLMを用いたクリーンアッププロセス
Googleでは、LLMを用いて実験用フラグのクリーンアップを自動化しました。プロセスは以下の通りです。
- 対象フラグの特定: 実験実行エンジンから、古くなったフラグのリストを取得しました。
- コード変更の生成:
- LLMを用いて、フラグが使用されているコード箇所を特定しました。
- LLMを用いて、テストファイル内の対応するテストフラグを特定しました。
- LLMを用いて、フラグへの参照、条件式、不要なコード、テストを削除しました。
- 変更のレビュー: 生成された変更は、コードレビュー担当者によってレビューされました。
以下は、この移行で実際に使用されたLLMへのプロンプト例です。
You are a software engineer trying to mark an experiment parameter for colleagues.
Your main task is to add comments the Flag in the test file that correspond to the runtime usage of the flag in the implementation file.
1. You are interested in the parameter {PARAMETER_TO_DELETE} in the experiment {EXPERIMENT_NAME}
2. In the test file add a comment with the parameter {PARAMETER_TO_DELETE} name to the test flags that corresponds to it.
3. The test flag that corresponds is one that has a similar name AND is used in methods where the original param is expected.
4. For example a method that takes {PARAMETER_TO_DELETE} in the implementation file might take the flag to mark in the test file.
5. Only add a comment in all lines where the flag you identified to corresponds to the parameter {PARAMETER_TO_DELETE} is used in the Test file.
クリーンアップ結果と効果
LLMは、不要になった関数の削除など、質の高いコード更新を生成できました。テストのクリーンアップは最も難しい部分でしたが、ほとんどの場合、モデルは正しい削除箇所を特定できました。
事例から得られた学びと今後の展望
これらの事例から、LLMを用いたコード移行は、大きな効果をもたらすことが分かりました。しかし、同時にいくつかの課題も明らかになりました。
LLMとASTベース手法の組み合わせの重要性
LLMは、コードの構文や意味を完全に理解しているわけではありません。そのため、LLMだけでコード移行を行うと、誤った変更を生成してしまう可能性があります。一方、ASTベースの手法は、コードの構造を正確に解析することができますが、複雑な変更に対応するのが難しい場合があります。
Googleの事例では、LLMとASTベースの手法を組み合わせることで、それぞれの長所を活かし、短所を補完しています。LLMは、コードの変更生成に重点を置き、ASTベースの手法は、変更箇所の特定や検証に用いられています。この組み合わせは、コード移行の効率化と品質向上に大きく貢献しています。
継続的なトレーニングと適応の必要性
LLMは、大量のデータから学習することで、その能力を発揮します。しかし、コードベースや移行要件は時間とともに変化するため、LLMも継続的にトレーニングし、適応させていく必要があります。
Googleでは、ユーザーの操作ログやフィードバックを活用して、LLMを継続的に改善しています。また、新しい移行プロジェクトに取り組む際には、そのプロジェクト固有のデータを用いてLLMをファインチューニングしています。
結論:LLMを用いたコード移行の有効性と将来性
本記事では、Googleが社内のコード移行にどのようにAIを活用しているのか、その具体的な事例と効果、今後の展望について解説しました。Googleでは、LLMをコード移行のための特注ソリューションとして活用し、大きな成果を上げています。
LLMを用いたコード移行は、まだ発展途上の技術です。今後は、以下のような課題に取り組む必要があります。
- LLMの精度向上: より正確なコード変更を生成できるように、LLMのトレーニング方法やモデルアーキテクチャを改善する。
- 適用範囲の拡大: より複雑な移行プロジェクトや、より多くのプログラミング言語に対応できるようにする。
- ユーザーエクスペリエンスの向上: 開発者がより簡単にLLMを用いたコード移行を行えるように、ツールやインターフェースを改善する。
これらの課題を解決することで、LLMを用いたコード移行は、今後さらに多くの企業で活用されるようになるでしょう。
開発生産性やAI対応にお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: