Googleがバグ発見時間を65%短縮した「投機的テスト」の秘密に迫る
公開日
Googleほどの巨大な開発現場では、日々繰り返されるソフトウェアテストが大きな課題となっています。テストに時間がかかり、バグの発見が遅れることは、開発のボトルネックとなり、生産性を低下させる要因となります。これは、多くの開発組織にとっても他人事ではない問題ではないでしょうか。
この記事では、Googleがこの難題にどのように立ち向かい、テストに関わる時間を大幅に短縮したのか、その秘密を探ります。Googleの研究者による論文「Speculative Testing at Google with Transition Prediction」(2025年) を基に、機械学習を活用した革新的なテスト戦略「投機的サイクル」とその驚くべき成果について、分かりやすく解説していきます。
終わらないテスト… Googleが直面したCI/CDの壁
Googleの開発環境は、その規模において特異です。数10億行のコードが一つの巨大なリポジトリ(モノレポ)で管理され、日々多数のエンジニアがコードを変更しています。このような環境で品質を維持するためには、継続的インテグレーション(CI)と、コードが提出された後に行われるテスト(Postsubmitテスト)が不可欠です。
Googleでは、Test Automation Platform (TAP) というシステムが、これらのテストを自動的に実行しています。しかし、コードベースとテストの数が指数関数的に増加するにつれて、TAPは大きな課題に直面していました。
- テストサイクルの遅延: コード変更後に影響を受ける全てのテストを実行する「包括的テストサイクル」には、1〜2時間かかることも珍しくありませんでした。
- リソースコストの増大: 増え続けるテストを実行するためには、膨大な計算リソースが必要となり、コストが増大していました。
- バグ発見の遅れ: テストサイクルの遅延は、バグの発見が遅れることを意味します。バグが発見されるまでに数時間かかると、修正を行う開発者は既に別の作業に移っており、コンテキストスイッチのコストが発生します。さらに、バグが修正されるまで他の開発者の作業をブロックしてしまう可能性もあり、開発者全体の生産性を低下させる大きな要因となっていました。
このような背景から、Googleはテストプロセスを根本的に見直し、より効率的なアプローチを模索する必要に迫られていたのです。
発想の転換:「全部テスト」から「賢くテスト」へ - 投機的サイクルの登場
増え続けるテスト要求とリソースの制約というジレンマに対し、Googleが出した答えの一つが「投機的サイクル(Speculative Cycles)」と呼ばれる新しいテスト実行戦略です。
従来の「包括的テストサイクル(Comprehensive Cycles)」が、前回のテスト以降に変更の影響を受けた可能性のある全てのテストを実行しようとするのに対し、投機的サイクルは発想を転換します。全てのテストを実行するのではなく、機械学習モデルを使って「次に失敗しそうなテスト」、つまりバグを発見する可能性が高いテストを予測し、それらを優先的に、かつ短い間隔(約20分ごと)で実行するのです。
このアプローチの目的は明確です。
- バグ発見の高速化: 最も重要な目的は、新しいバグがコードベースに混入してから発見されるまでの平均時間(MTTD: Mean Time To Detection)を短縮することです。
- リソース効率: 全てのテストを実行するわけではないため、計算リソースの使用を抑えることができます。
- 開発者体験の向上: バグが早期に発見されれば、開発者は迅速に対応でき、コンテキストスイッチのコストや他の開発者への影響を最小限に抑えられます。
投機的サイクルは、限られたリソースの中で、いかに賢くテストを実行し、バグ発見の効率を最大化するかという問題に対する、Googleの野心的な試みなのです。
効果は絶大!バグ発見時間を中央値で65%も短縮
では、投機的サイクルは実際にどれほどの効果を上げたのでしょうか?Googleは、3ヶ月間にわたる本番環境のデータ(1200億以上のテストとサイクルのペア、770万件のバグ発生、約2万件のユニークなバグ原因を含む)を用いて、その効果を検証しました。
テスト結果が出るまでの時間が劇的に改善
最も注目すべき結果は、新しいバグが検出されるまでにかかる時間(Breakage Detection Latency)の大幅な短縮です。
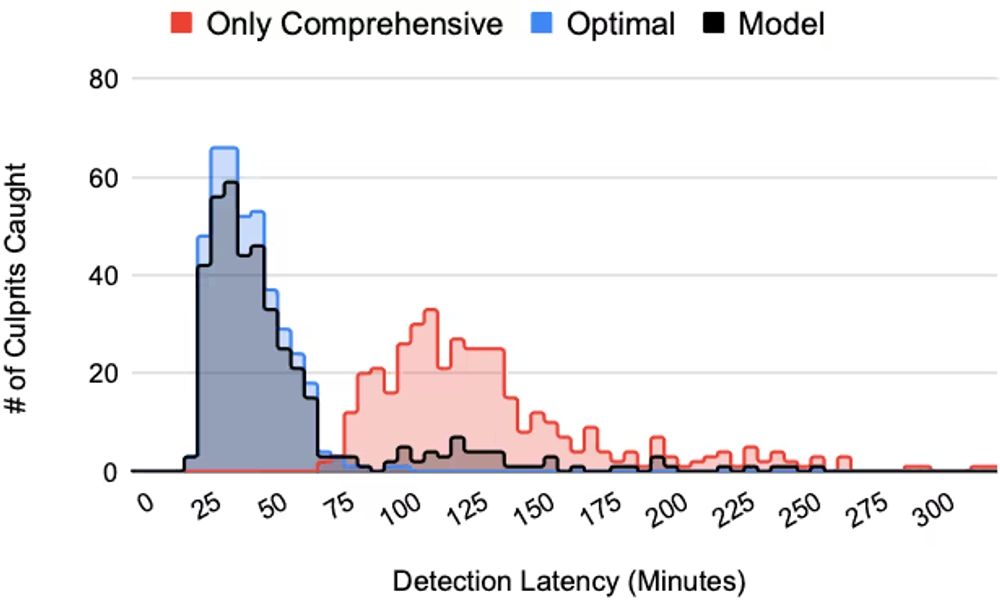
下の図は、バグがコミットされてから検出されるまでの時間(分)の分布を示しています。従来の包括的サイクルのみ(“Only Comprehensive”、赤色)では、検出までの中央値(p50)が107分かかっていました。一方、投機的サイクルを導入した場合(“Model”、黒色)、検出までの中央値は37分にまで短縮されました。これは、約65%もの時間短縮に相当します。“Optimal”(青色)は常に正しいテストを選択できる理想的なモデルを示しており、提案手法が理想には及ばないものの、従来手法から大幅な改善を実現していることが分かります。
バグ検出レイテンシの比較グラフ
この結果は、投機的サイクルがバグをより迅速に開発者にフィードバックし、問題の早期解決に貢献することを示唆しています。
影響の大きなバグほど見つけやすい?
投機的サイクルは、単にバグ発見を早めるだけでなく、特に影響範囲の大きな、つまり修正の優先度が高いバグを効率的に見つけ出す傾向があることも示されました。
そもそも、Googleのコードベースで発生するバグの多くは、影響範囲が限定的です。下の図を見ると、約半数のバグは1つのターゲット(テストやビルド)しか破壊しておらず、10個以上のターゲットを破壊するような影響の大きなバグは全体の約4分の1程度であることが分かります。
影響範囲の大きなバグの割合を示すグラフ
では、投機的サイクルは、これらのバグをどれだけ効率的に検出できるのでしょうか?以下の図は、テスト実行の「予算」(影響を受ける全ターゲットのうち、何%を実行するか)に対して、どれだけの割合のバグを検出できたか(検出率)を示しています。
注目すべきは、影響の大きいバグ(“AtLeast(10)“、つまり10個以上のターゲットを破壊するバグ)に対する検出率(青丸)が、全てのバグ(“AtLeast(1)“、赤三角)に対する検出率よりも高い点です。例えば、全ターゲットの25%を実行するという予算で、影響の大きいバグの約85%を検出できています。これは、ランダムにテストを選択するベースライン(赤破線)と比較しても非常に高い検出率です。
影響の大きいバグを早期に発見できることは、問題のあるコード変更を自動的に元に戻す「自動ロールバック」を効果的に機能させる上でも重要であり、コードベースの健全性維持に大きく貢献します。
テスト予算に対するバグ検出率の比較グラフ
なぜ予測できる?核心技術「Transition Prediction」の仕組み
投機的サイクルの驚くべき効果は、その中核をなす機械学習モデル「Transition Prediction (TRANSPRED)」によって支えられています。TRANSPREDは、どのテストが「次に失敗しそうか」を高精度で予測する役割を担っています。
テストの「失敗」を事前にキャッチ
TRANSPREDが予測しようとしているのは、あるテストターゲットが、それまで成功していた状態から、次のテストサイクルで失敗する状態へと「状態遷移」するかどうか、です。言い換えれば、「どのテストが、最近のコード変更によって新たに壊された可能性が高いか」を予測します。
この予測を実現するために、Googleは高速かつ計算コストの低い機械学習モデルを採用しました。具体的には、Gradient Boosted Decision Trees (GBDT) や Random Forests といったツリーベースのアンサンブル学習モデルが利用されています。これらのモデルは、大量のデータと多様な特徴量を扱いつつ、予測に必要な計算を高速に行えるため、約20分ごとという短いサイクルでの予測実行に適しています。
モデルは何を手がかりに予測しているのか?
では、TRANSPREDモデルは、具体的にどのような情報を手がかりにして「失敗しそうなテスト」を予測しているのでしょうか?論文では、主に以下のようなメタデータが特徴量として利用されていると説明されています。
以下の表に、利用されている特徴量の具体例を示します。静的な情報(言語など)と動的な情報(実行履歴など)を組み合わせることで、より精度の高い予測を目指しています。
予測の手がかりとなる情報(特徴量)の例
| 特徴量セット | タイプ | 特徴量の例 |
|---|---|---|
| 基本 | コミットメタデータ | レビュアー数、承認者数、関連バグ数、コード変更行数 |
| 基本 | Presubmitテスト履歴 | 過去28日間でのテスト成功/失敗回数 |
| 基本 | Postsubmitテスト履歴 | 過去28日間でのテスト成功/失敗/不安定(Flaky)実行回数 |
| 基本 | コミット特徴量 | ビルド依存グラフ最短距離 |
| 拡張 | コミット特徴量 | botによるコミット数 |
| 拡張 | ターゲットメタデータ | ターゲット言語(例: Java, C++, sh)、ターゲットタイプ(ビルド vs テスト) |
| 拡張 | 拡張追加履歴 | 過去28日間での真のバグ(検証済み)発生回数 |
重要なのは、これらの特徴量がコードの内容そのものではなく、コードやテストを取り巻く状況を示すメタデータである点です。これにより、言語やフレームワークに依存しにくく、比較的低コストで情報を収集・利用できるという利点があります。
「滅多に起きないバグ」をどう扱うか?
Postsubmitテストでバグが発見されるケースは、実は非常に稀です。論文によれば、テストターゲットとサイクルのペアのうち、実際に状態遷移(成功から失敗へ)が起こるのは 0.0001% 程度、つまり100万回に1回というレベルです。
これは、機械学習モデルの学習においては「Super Extreme Class Imbalance(超極端なクラス不均衡)」と呼ばれる非常に難しい問題を引き起こします。「失敗」という予測したいクラス(少数派クラス)のデータが、「成功」というクラス(多数派クラス)に比べて圧倒的に少ないため、モデルは単純に「常に成功する」と予測するだけでも高い正解率を出せてしまい、本当に重要な「失敗」の予測精度が上がりにくくなるのです。
この問題に対処するため、TRANSPREDでは学習時にダウンサンプリングという手法を用いています。これは、多数派クラスである「成功」のデータの一部をランダムに間引くことで、少数派クラスである「失敗」とのデータ数の比率の差を縮小するアプローチです。
より賢く予測するためのヒント:モデル性能を高める要因
TRANSPREDモデルが高い予測性能を発揮するためには、いくつかの重要な要因があります。Googleは、モデルの設計や学習方法を検討する中で、以下の点が予測精度に大きく影響することを発見しました。これらは、同様の仕組みを自社で導入・改善する際の重要なヒントとなるでしょう。
「いつ」のデータで学習させるのが効果的?
機械学習モデルの性能は、学習に使うデータの「鮮度」や「期間」に影響されることがあります。TRANSPREDの場合、どのくらいの期間の過去データを使ってモデルを学習させるのが最適なのでしょうか?
以下の表は、学習データの期間を変えてモデル性能を比較した結果です。この結果を見ると、学習期間が1週間の場合よりも3週間の場合の方が性能が高く、さらに5週間に伸ばすと逆に性能が低下しています。
学習期間と特徴量が予測精度に与える影響
| 学習データ期間 | 基本特徴量セットの予測精度 | 拡張特徴量セットの予測精度 |
|---|---|---|
| 1週間 | 0.790 | 0.791 |
| 2週間 | 0.779 | 0.808 |
| 3週間 | 0.815 | 0.824 |
| 4週間 | 0.808 | 0.817 |
| 5週間 | 0.778 | 0.782 |
これは、あまりに短期間のデータだけでは学習に必要なパターンを捉えきれず、逆に長期間すぎると古い情報(既に修正されたバグのパターンなど)のノイズが悪影響を与える可能性を示唆しています。この実験では、3週間の学習期間が最適なバランスであると結論付けられています。また、特徴量セットについても、基本セットよりも、ターゲット履歴などを追加した拡張特徴量セットの方が一貫して高い性能を示しており、利用する特徴量の選択も重要であることが分かります。
クラス不均衡にどう向き合うか? データ処理の影響
TRANSPREDモデルの学習においては、バグ発生が非常に稀であるという「超極端なクラス不均衡」への対処が不可欠です。この不均衡にどう対応するかが、モデルの予測精度を大きく左右します。Googleは、ダウンサンプリング(多数派クラスのデータを減らす手法)とアップウェイティング(少数派クラスの重要度を高める手法)という二つのアプローチの影響を評価しました。
以下の表は、多数派クラス(成功)をどの程度削減するかを示す「ダウンサンプリング率」と、少数派クラス(失敗)の重要度を学習時にどれだけ高めるかを示す「アップウェイト係数」の組み合わせが、予測精度にどう影響するかを示しています。
クラス不均衡への対処法が予測精度に与える影響
| 多数派クラス ダウンサンプリング率 | 少数派クラス アップウェイト係数 | 予測精度 |
|---|---|---|
| 0.01 | 1 | 0.824 |
| 0.005 | 1 | 0.814 |
| 0.001 | 1 | 0.815 |
| 0.01 | 400 | 0.818 |
| 0.005 | 100 | 0.822 |
| 0.001 | 40 | 0.826 |
| 太字は全体の検証で利用したモデルの設定 |
これらの結果は、クラス不均衡への対処がモデル性能に重要である一方で、その調整は単純ではなく、試行錯誤が必要であることを示唆しています。
まとめ:Googleの「投機的テスト」が示す、未来のテスト効率化
本記事では、Googleが開発した「投機的サイクル」と、それを支える機械学習モデル「Transition Prediction (TRANSPRED)」について、論文に基づき解説しました。
Googleは、この革新的なアプローチによって、新しいバグを発見するまでにかかる時間を中央値で約65%も短縮することに成功しました。これは、テストの遅延という巨大な課題に対する有効な解決策であると同時に、開発者の生産性向上にも大きく貢献するものです。
このGoogleの事例から、私たちは以下の重要な点を学ぶことができます。
- テスト戦略の見直し: 全てのテストを網羅的に実行するだけが唯一の解ではありません。リスク(バグの可能性)に基づいてテストの優先度を付け、賢く実行するという「投機的」なアプローチは、特に大規模な開発環境において有効な戦略となり得ます。
- 機械学習の活用: テストの失敗予測に機械学習を用いることで、人間では不可能な規模と速度での最適化が可能になります。特に、コードの内容自体ではなく、コミット履歴やテスト実行履歴といったメタデータを活用するアプローチは、比較的低コストで導入できる可能性があります。
- データに基づいた改善: モデルの性能は、学習データの期間や特徴量の選択、クラス不均衡への対処法など、様々な要因に影響されます。実際のデータを用いて効果を測定し、継続的に改善していくことが重要です。
投機的サイクルは、Googleという特定の環境における取り組みですが、その根底にある思想や技術は、多くのソフトウェア開発組織におけるテスト効率化の取り組みに、新たな視点と可能性を示唆していると言えるでしょう。
開発生産性やチームビルディングにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: