AIエージェントがバグを直す?Googleの自動プログラム修復AIエージェントの実験結果
公開日
開発生産性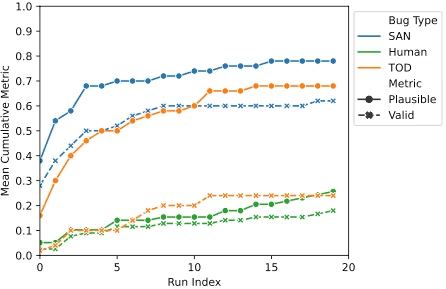
近年、ソフトウェア開発の現場では、バグ修正の効率化が大きな課題となっています。特に、複雑化するコードベースにおいて、人手によるバグの特定と修正には膨大な時間と労力がかかります。そんな中、AIの発展、特に大規模言語モデル(LLM)の進化により、自律的にバグを修正することを目指す、エージェントベースの自動プログラム修復技術への期待が高まっています。
本記事では、Googleの研究チームが発表した論文「Evaluating Agent-based Program Repair at Google」に基づき、エージェントベースのプログラム修復の現状と課題、そして将来性について解説します。
エージェントベースのプログラム修復とは?
従来の自動プログラム修復は、あらかじめ定義されたルールやテンプレートに基づいてバグの特定と修正を行うものが主流でした。これに対し、エージェントベースのプログラム修復では、LLMを搭載したエージェントが、自律的にバグの特定、修正、テスト、そして修正パッチの作成までを行います。人間がエージェントを操作するような、人間とエージェントのインターフェースを構築することで、より複雑なバグにも対応できる可能性があります。
エージェントベースのプログラム修復の主なメリットは、以下の通りです。
- 開発効率の向上: バグ修正にかかる時間と労力を削減し、開発者はより創造的な業務に集中できます。
- ソフトウェア品質の向上: より多くのバグを迅速かつ正確に修正することで、ソフトウェアの品質向上に貢献します。
- 属人化の解消: 特定のエンジニアのスキルに依存することなく、安定した品質でバグ修正を行うことができます。
Googleのエージェント「Passerine」
Googleが開発した「Passerine」は、 SWE-Agent に触発されて作られたエージェントです。Passerineは、「思考」「行動」「結果」をステップごとに繰り返し、それらの情報を次のステップに活かしながら、バグの修正を試みます。 Googleの内部開発環境と連携して動作するように設計されており、ファイル閲覧、ファイル編集、テスト実行など、必要最小限のコマンドのみを使用します。これは、Googleのテスト実行環境が既に十分なコンテナ化を提供しているためです。
Googleにおける評価実験
Googleの研究チームは、Passerineの性能を評価するために、Googleの内部イシュートラッキングシステム(GITS)から収集したバグデータを用いて、新たな評価セット「GITS-Eval」を構築しました。GITS-Evalは、人間が報告したバグ78件と、機械が報告したバグ100件で構成されています。
GITS-Evalの構築方法
GITS-Evalは、下図に示すような多段階のフィルタリングプロセスを経て構築されました。
まず、アクセス制限がなく、バグタイプが「バグ」であり、修正済みで、1つのバグに1つのパッチが対応し、内部のバグで、バグの説明が空でない、約8万件のバグを収集しました(Phase 0)。
次に、修正が妥当かどうかを判断できる、人間が報告したバグと、機械が報告したバグをそれぞれフィルタリングしました。具体的には、テストできないソースファイルの除外や、テストファイルやソースファイルに変更があるかを確認しました(Phase 1)。
続いて、マルチメディアを含まない、パッチサイズが一定以下、実行時間が長すぎない、といった基準で、Passerineが実行可能なバグに絞り込みました(Phase 2)。
最後に、サンプリングを行い、実行ベースのテスト妥当性を確認しました。最終的に、人間が報告したバグ78件、機械が報告したバグ100件(自動テスト順序依存性検出ツール(TOD)によるもの50件、自動サニタイザー(SAN)によるもの50件)が、GITS-Evalとして選定されました(Phase 3)。
GITS-EvalとSWE-Benchの比較
Passerineの性能を評価する上で、どのようなデータセットを用いるかは重要な問題です。特に、PasserineはGoogleの内部環境で動作するように設計されているため、Googleの実際の開発現場におけるバグの特性を反映したデータセットを用いることが望ましいと考えられます。そこで、Googleの内部イシュートラッキングシステムから構築されたGITS-Evalと、エージェントベースのプログラム修復の分野で広く用いられているオープンソースのデータセットである SWE-Bench を比較することで、GITS-Evalの特性を明らかにします。
言語の多様性
SWE-Benchは、GitHub上の一般的なPythonリポジトリから収集されたバグと修正のデータセットであり、多くの先行研究で用いられています。 GITS-Evalは、Googleの内部イシュートラッキングシステムから収集されたバグデータに基づいているため、Pythonだけでなく、C++、Java、TypeScript、Kotlinなど、多様なプログラミング言語のバグを含んでいます。これは、Passerineが様々な言語で書かれたコードのバグを修正できるかどうかを評価する上で、重要な特性となります。
変更のサイズと分散
下記の図は、GITS Phase 1のバグとSWE-Benchのバグを、抽出された識別子(a)、変更ファイルの数(b)、修正範囲(c)、変更ブロック数(d)、変更されたコードの行数(e)の観点から比較したものです。

GITSのパッチは、SWE-Benchのパッチに比べて、変更されるファイル数が多く(最大2倍)、変更がより多くのファイルに分散しており、変更ブロック数も多い傾向にあります。また、変更されたコードの行数も、GITSの方が大幅に多くなっています。
ローカライズの難易度
下記の図は、GITS-Evalの機械報告バグとSWE-Bench-Liteのバグを、同様の観点から比較したものです。

バグの説明に含まれる、コードに関連する可能性のある識別子の数は、SWE-Bench-Liteと比べてGITS-Evalの方が少なくなっています。これは、GITS-Evalの方が、バグの特定が難しい可能性があることを示唆しています。
Passerineの性能評価
生成されたパッチのplausible patch rateとvalid patch rate
Passerineは、20のバグ報告データとGemini 1.5 Proを用いて実験を行いました。その結果、機械によって報告されたバグの73%、人間によって報告されたバグの25.6%に対して、バグテストをパスするパッチ(plausible patch)を生成できました。
さらに、手動でパッチを検査したところ、機械によって報告されたバグの43%、人間によって報告されたバグの17.9%に対して、正解パッチと意味的に等価なパッチ(valid patch)を少なくとも1つ生成できたことが分かりました。
試行回数(Run Index)の増加に伴うplausible patchとvalid patchの生成率
k回のパッチ生成におけるplausible patchとvalid patchの生成率
実験結果から得られた洞察
実験の結果、Passerineは、バグの種類に応じて異なるコマンドを使い分けることが明らかになりました。例えば、人間によって報告されたバグに対しては、コード検索やファイル閲覧といった、バグの特定に役立つコマンドを多用する傾向が見られました。一方、機械によって報告されたバグに対しては、テストの実行や、ファイルの編集といった、バグの修正に直接関わるコマンドを多用する傾向が見られました。
また、Passerineは、バグ報告が詳細であればあるほど、より高い精度でバグを修正できることも分かりました。特に、機械によって報告されたバグは、再現手順やエラーメッセージなど、バグの特定に役立つ情報が豊富に含まれているため、Passerineは高い性能を発揮しました。
今後の課題と展望
エージェントの性能向上
Passerineを含むエージェントベースのプログラム修復技術の性能は、まだ改善の余地があります。特に、人間によって報告されたバグに対する性能は、機械によって報告されたバグに比べて低い水準に留まっています。
下記の図は、バグの種類別に、Passerineがどのようなコマンドを、どのステップで実行したかを示したものです。
この図から、人間が報告したバグの場合、Passerineは序盤にcode_searchやcatといった、コード特定のためのコマンドを多く使用していることが分かります。一方、SANやTODの場合は、序盤からbazelコマンドでテストを実行していることが分かります。このように、バグの種類によって、Passerineが実行するコマンドの傾向は大きく異なります。
下記の図は、Passerineがパッチを生成できなかったケースにおいて、エージェントが編集したファイルと、正解のファイルとの間の、ファイルシステム上の距離を示したものです。
機械によって報告されたバグの場合、Passerineは、正解のファイルに近いファイルを編集する傾向があることが分かります。これは、機械によって報告されたバグには、バグの特定に役立つ情報が豊富に含まれているためと考えられます。しかし、人間によって報告されたバグの場合は、正解のファイルとはかけ離れたファイルを編集してしまうケースが多く、バグの特定が難しいことを示唆しています。
今後は、より詳細なバグ報告の活用や、エージェントの推論能力の向上、軌跡分析による最適化などが、性能向上に向けた鍵となるでしょう。
実用化に向けた課題
エージェントベースのプログラム修復技術を実用化するためには、性能向上に加えて、以下のような課題を解決する必要があります。
- 安全性の確保: エージェントが生成したパッチが、新たなバグを生み出したり、セキュリティ上の問題を引き起こしたりしないことを保証する必要があります。
- 開発者との協調: エージェントは、開発者の意図を理解し、開発者と協力してバグを修正する必要があります。
- 説明責任の所在: エージェントが生成したパッチに問題があった場合、誰が責任を負うのかを明確にする必要があります。
結論
エージェントベースのプログラム修復は、ソフトウェア開発の効率化と品質向上に大きく貢献する可能性を秘めた技術です。Googleの研究成果は、その可能性を実証するとともに、実用化に向けた課題を明らかにしました。今後の技術発展により、エージェントがバグを直す時代が到来するかもしれません。そして、この技術の進展には、私たち人間とAIとの協調関係の構築が不可欠となるでしょう。
開発生産性やAI対応にお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: