あなたのCI、本当に成功していますか?見えないエラー「サイレント失敗」の実態と対策
公開日
開発プロセスの高速化に不可欠なCI/CDパイプライン。ビルド結果に表示される「緑のチェックマーク」は、私たちに安心感を与えてくれます。しかし、その「成功」が、実はタスクが完了していない「成功の錯覚」だとしたらどうでしょうか?この見えないエラーは「サイレント失敗」と呼ばれ、気づかぬうちにバグを本番環境に送り込み、開発チームの信頼を静かに蝕んでいきます。
本記事では、2025年に発表された学術研究「On the Illusion of Success: An Empirical Study of Build Reruns and Silent Failures in Industrial CI」に基づき、この厄介な「サイレント失敗」の正体を徹底的に解明します。データが示す驚くべき実態から、具体的な原因、そして明日から実践できる対策まで、CI/CDプロセスの信頼性を向上させるための知識を解説します。
「サイレント失敗」とは何か? - CIにおける見えない落とし穴
「サイレント失敗」(Silent Failures)とは、CI/CDパイプラインにおいて、ビルドジョブが成功とマークされたにもかかわらず、実際にはそのタスクの一部または全てが完了していない現象を指します。
最大の特徴は、その名の通り「静か」に失敗することで、多くの場合、ジョブのログに明確なエラーや警告の痕跡を残しません。例えば、キャッシュファイルのアップロードに失敗しても、ログ上は「Job succeeded」と表示されることがあります。
従来から知られている「間欠的失敗」(ネットワークの不安定性などで時折失敗する現象)は、ジョブが明示的に失敗するため、開発者は問題の存在を認識できます。しかし、サイレント失敗は成功に見えるため、問題の発見を著しく遅らせます。この遅延が、以下のような深刻な結果を招くのです。
- フィードバックの遅延: バグや設定ミスが長期間見過ごされる。
- 信頼性の低下: 開発者がビルドの「成功」を信じられなくなり、確認のために手動で何度もジョブを再実行するようになる。
- コストの増大: 無駄な再実行がCIサーバーのリソースを圧迫し、コストが増加する。
- バグの混入: 最悪の場合、不完全なビルド成果物が本番環境にデプロイされ、ユーザーに影響を与えてしまう。
驚くべき実態 - データが語る「サイレント失敗」の蔓延
この見えない脅威は、一体どれくらいの頻度で発生しているのでしょうか。本研究では、ある大手通信企業の81の産業プロジェクトから収集された14万件以上のジョブデータを分析し、その実態を明らかにしました。
データが示す実態1:再実行の半数以上は「成功したジョブ」だった
分析の結果、再実行されたジョブのうち、実に51%が一度は「成功」と表示されたジョブでした。これは、明示的に「失敗」したジョブの再実行(44%)を上回る割合です。このデータは、開発者がビルドの成功表示を信用できず、何か問題が起きていることを疑って再実行しているケースが非常に多いことを示唆しています。
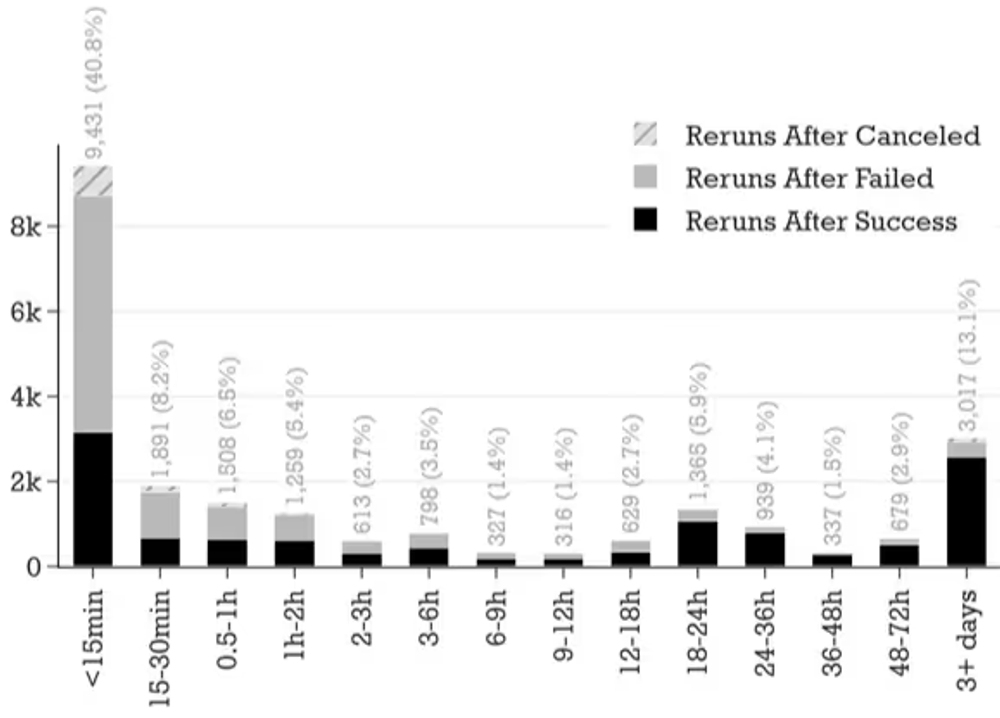
図表1:再実行前後のジョブステータスの遷移
データが示す実態2:発見が非常に遅く、コストへの影響も甚大
さらに深刻なのは、サイレント失敗が発見されるまでの時間の長さです。明示的な失敗はすぐに再実行されるのに対し、サイレント失敗の発見には中央値で約7時間、平均では4.6日もかかっていました。再実行の3割以上が2日後に行われているという事実は、問題が長期間気づかれないままであることを物語っています。
図表2:再実行されたジョブのステータス別時間遅延の分布
この発見の遅れと、それに伴う無駄な再実行は、CIの運用コストにも大きな影響を与えます。調査では、サイレント失敗に起因する再実行が、CIサーバーの 無駄な消費時間の約半分(48%) を占めていることが判明しました。
あなたのプロジェクトは大丈夫? - サイレント失敗を招く危険信号
サイレント失敗は、特定の条件下で発生しやすくなる傾向があります。以下のチェックリストを参考に、ご自身のプロジェクトに潜むリスクを評価してみましょう。
危険度チェック:こんな時、サイレント失敗が起きやすい
- ジョブの種類: テストジョブや静的解析ジョブを多用していますか?
- これらのジョブは、レポートファイルなどの「アーティファクト」を扱うことが多く、その操作でサイレント失敗が起きやすいため、再実行される確率がそれぞれ89%、49%高くなります。
- プロジェクトの言語: ShellスクリプトやHCL (HashiCorp Configuration Language) を多用していますか?
- IDEによる支援が限定的なこれらの言語は、エラーを握りつぶす記述を見逃しやすいため、再実行される確率がそれぞれ17%、5%高くなります。
- 開発体制: 特定の開発者が頻繁にジョブを再実行していませんか?
- 過去5回のジョブで再実行が多かった開発者は、次のジョブも再実行する可能性が著しく高いという、非常に強い相関関係が見られました。これは、その開発者が現在担当しているタスクやコード領域に、根本的な不安定要因が潜んでいる可能性が高いことを示唆しています。
- 時期: 年末年始(11月〜2月頃) にビルドの不安定性が増していませんか?
- データ分析の結果、この期間にジョブが再実行される確率が高まるという季節性が確認されました。これは、多くの企業で年末のリリースラッシュや休暇中の人員不足、年始のインフラ更新などが重なり、CIプロセス全体が不安定になりがちなためと考えられます。
図表3:年間を通じた成功ジョブの再実行確率と季節性の関係
安全度チェック:こんな時は比較的リスクが低い
- 開発プロセス: フィーチャーブランチでの開発が徹底されていますか?
developブランチに直接コミットするよりも、フィーチャーブランチで作業する方が、ジョブが再実行される確率は47%低くなりました。
- チーム構成: 経験豊富な開発者がレビュープロセスを支えていますか?
- プロジェクトへのコミット貢献度が高い開発者がトリガーしたジョブは、再実行される確率が低い傾向にありました。
原因を特定する - 最も一般的なサイレント失敗トップ3とその対策
では、具体的にどのような原因でサイレント失敗は発生するのでしょうか。GitLabで報告された92件の公開イシューを分析した結果、11のテーマが浮かび上がりました。ここでは特に頻度の高かったトップ3を紹介します。
第1位:アーティファクト操作エラー (Artifact Operation Errors)
テストレポートやビルド成果物などの「アーティファクト」のアップロードやダウンロードに失敗しても、ジョブ自体は成功とマークされてしまうケースです。
- 原因: ストレージへのアクセス権限の問題、ファイルパスの間違い、アーティファクトのサイズ超過など。
- 対策: ジョブの最後にアーティファクトの存在を明示的にチェックするステップを追加し、存在しない場合はジョブを失敗させる。
第2位:キャッシュエラー (Caching Errors)
依存関係などを保存するキャッシュの作成や読み込みに失敗し、後続のジョブに影響が出るにもかかわらず、キャッシュ操作を行ったジョブは成功と表示されるケースです。
- 原因: キャッシュストレージの容量不足、キャッシュキーの重複による上書き、ネットワークの問題など。
- 対策: キャッシュストレージの定期的なクリーンアップや、キャッシュ管理システムのバージョンアップを行う。
第3位:無視された非ゼロ終了コード (Ignored Non-Zero Exit Codes)
スクリプト内でエラーが発生し、非ゼロの終了コードが返されているにもかかわらず、CIシステムがそれを検知せず、ジョブを成功として扱ってしまうケースです。
- 原因: PowerShellの
if-elseブロック内でのexitコールや、set -eオプション(エラー発生時に即座にスクリプトを終了させる設定)の欠如など。 - 対策: スクリプトの冒頭で
set -eを宣言し、エラーを確実にCIシステムに伝えるようにする。
その他のサイレント失敗
トップ3の他にも、以下のような原因でサイレント失敗が発生することが報告されています。ご自身の環境で似たような問題が起きていないか、チェックリストとしてご活用ください。
- インフラ構成の問題
- CIワーカーのタイムアウト値やリソース制限が厳しすぎないか確認する。
- セキュリティスキャン失敗
- スキャンツールの依存関係不足や、ツール自体のバージョンアップを検討する。
- スクリプト実行のスキップ
- コンテナのイメージ設定(エントリーポイント)が、意図せずスクリプト実行を上書きしていないか確認する。
- デプロイ後の問題
- デプロイ成功後に、アプリケーションが実際に利用可能かヘルスチェックを行う。
- 無視されたテスト失敗
- テストフレームワークが返す終了コードをCIが正しくハンドリングしているか確認する。
- サイレントCurlエラー
- スクリプト内でエラーを抑制する
curl -sや--silentといったオプションの使用を避ける。
- スクリプト内でエラーを抑制する
- 無効なCI変数
- 変数のスコープ(例:保護されたブランチ限定など)が意図した通りか確認する。
- 構文エラー
- CI設定ファイルを分割して利用する際は、構文チェックが正しく機能するか注意する。
今すぐできる対策 - CIパイプラインの信頼性を取り戻す方法
サイレント失敗は厄介な問題ですが、その存在を認識し、原因を理解することで、対策を講じることが可能です。
【開発チーム向け】事後検証ステップを標準プロセスに組み込む
最も効果的な対策は、「成功したからOK」と考えるのをやめ、重要なジョブの後には必ず検証ステップを設けることです。
- アーティファクト生成ジョブの後: 「テストレポートは本当に存在するか?」「コンテナイメージはレジストリに正しくプッシュされたか?」を確認するジョブを追加します。
- デプロイジョブの後: 「新しいバージョンは本当に環境に反映されたか?」をヘルスチェックAPIなどで確認するジョブを追加します。
この「疑う」一手間が、下流での大きな問題を防ぎます。
【ツール選定・運用者向け】CIツールの機能を最大限に活用する
CIツール自体も、サイレント失敗を防ぐための機能を提供・改善していく必要があります。
- ツールの選定: GitLabの「needs」キーワードのように、アーティファクトの依存関係を明示的に定義できる機能を持つツールを選びましょう。
- 設定の見直し: キャッシュやストレージへのアクセスエラーがサイレントに処理されていないか、CIツールの設定を確認し、エラーを明示的に通知するように変更します。
- アンチパターンの共有: タイムアウト値が短すぎる、スクリプト内でエラーを無視するコマンド(例:
curl -s)を使っているなど、チーム内でサイレント失敗を招きやすいアンチパターンを共有し、避ける文化を醸成しましょう。
結論:緑のチェックマークの先を見据えて
CI/CDにおける「成功」の緑のチェックマークは、開発プロセスにおける重要なマイルストーンです。しかし、その表示の裏に「サイレント失敗」という見えない脅威が潜んでいることを、私たちは認識しなければなりません。
本研究が明らかにしたように、サイレント失敗は決して稀なケースではなく、どの開発現場にも起こりうる身近な問題です。しかし、その存在を認識し、データに基づいて発生しやすい状況や原因を理解することで、具体的な対策を講じることが可能です。
ジョブの実行後に成果物を検証するプロアクティブなアプローチを取り入れ、CIプロセス全体の信頼性を向上させること。それこそが、ビルドの「成功」を単なる表示ではなく、真の品質保証へと昇華させるための鍵となるのです。
開発生産性やチームビルディングにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: