「コード・アズ・ハーネス」とは?AIエージェントを自律させるのはコードだった
公開日
開発生産性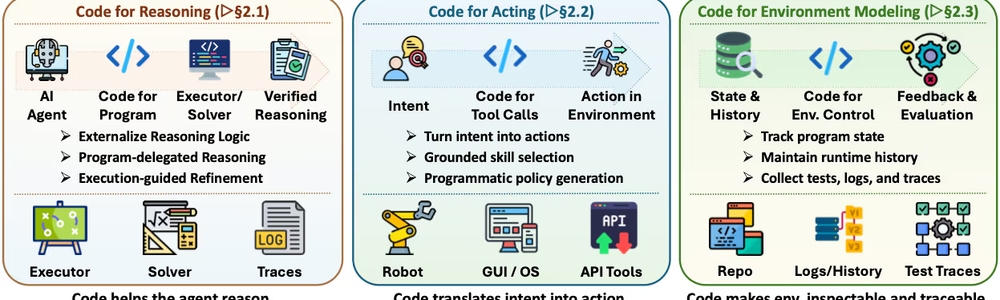
最近の大規模言語モデル(LLM)は、自律的にタスクを遂行するAIエージェントとしての応用が進んでいます。これまでAIにおける「コード生成」といえば、人間が与えた指示に従ってプログラムを出力するだけの機能と見なされがちでした。しかし現在、コードはAIエージェント自身が論理的に考え、外部環境と相互作用し、間違いを修正するための重要なシステム基盤へと変化しています。
本記事では、イリノイ大学アーバナ・シャンペーン校(UIUC)やMeta、スタンフォード大学の研究者らが発表した論文「Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems」に基づき、コードがエージェントの基盤(ハーネス)としてどのように機能するのかを解説します。
エージェントハーネスとは何か?コードが果たす3つの機能
本研究は、AIエージェント関連の文献を体系的に整理し、コードを中心に据えたエージェントシステムの構造を3つの層に分類した包括的なサーベイです。
言語モデルを自律的なエージェントに変えるための最も基本的な設計上の問いは、「モデルとタスク環境を何でつなぐか」です。本論文は、その答えが「コード」であると主張しています。自然言語とは異なり、コードは実行可能であり、中間状態を構造化して保存でき、エラーの検証が容易です。エージェントがタスクをこなすための土台(インターフェース)として、コードは以下の3つの役割を担います。
1. 推論の外部化と検証
人間が頭の中で計算するのには限界があるように、LLMも自然言語だけで複雑な論理や計算を追うと失敗しやすくなります。そこで、推論プロセスをコードとして出力し、外部の実行環境(Pythonインタープリタや数式ソルバーなど)に計算を委ねる手法が取られます。これにより、推論の各ステップが実行可能な形で明確になり、間違いが起きた際もエラーログから容易に原因を特定できるようになります。
2. 物理・デジタル環境における行動の基盤
エージェントがソフトウェアや物理的なロボットを操作する際、自然言語の指示を直接的な動作に結びつけるのは困難です。コードは、モデルの意図をAPI呼び出しやロボットの制御コマンドといった実行可能な行動に変換します。これにより、環境の制約(ロボットの可動域やソフトウェアの権限など)に従いながら、安全かつ正確に行動できるようになります。
3. 実行可能な環境モデリング
複雑なタスクを完了するためには、エージェントが現在の環境状態を把握しておく必要があります。コードは、シミュレーターやテスト環境、リポジトリといった形で世界を表現します。エージェントは環境の状態をプログラムの変数やデータ構造として保持・参照することで、次にとるべき行動を正確に判断できます。
 図表1:コードが果たすインターフェースとしての役割(推論、行動、環境モデリング)
図表1:コードが果たすインターフェースとしての役割(推論、行動、環境モデリング)
エージェントを自律稼働させるハーネスのメカニズム
コードをインターフェースとして確立した後、エージェントが長期的なタスクを安定して遂行するためには、システムレベルでのメカニズムが必要です。論文では、これを「ハーネスのメカニズム」として整理しています。
計画とメモリ管理による長期タスクの遂行
実世界のソフトウェア開発タスクは、一度のコード生成で完了することはほとんどありません。エージェントは目標を細かく分解し、依存関係を整理して計画を立てる必要があります。また、LLMのコンテキストウィンドウ(一度に処理できる情報量)には限界があるため、過去の実行履歴やリポジトリの情報を効率的に保存・検索するメモリ管理が不可欠です。作業メモリには直近のタスク状態を保持し、長期メモリには過去の成功・失敗体験を蓄積することで、エージェントは文脈を見失うことなく作業を継続できます。
PEVループ(計画・実行・検証)による制御
エージェントの行動を制御する中核となるのが「Plan-Execute-Verify(PEV)」と呼ばれるループです。これは、単にエラーを修正するデバッグ作業を超えた、システム全体の統制プロセスを指します。
- 計画(Plan): 変更の意図や検証の基準を明確にします。
- 実行(Execute): 権限が制限された安全なサンドボックス環境内でコードを実行します。
- 検証(Verify): コンパイラ、静的解析ツール、ユニットテストなどの客観的なセンサーを用いて結果を評価し、次に進むか、修正するか、人間に判断を仰ぐかを決定します。
このループにより、エージェントは無秩序な動作を避け、安全かつ着実にタスクを完了へと導くことができます。
 図表2:PEVループ(計画・実行・検証)によるハーネス制御の概要
図表2:PEVループ(計画・実行・検証)によるハーネス制御の概要
マルチエージェントによるコード生成のスケールアップ
タスクが複雑化すると、単一のエージェントですべてを処理することには限界が生じます。そこで、役割を分担した複数のエージェントを連携させるアプローチが注目されています。
役割分担と共有プログラム状態の同期
マルチエージェントシステムでは、計画担当、コーディング担当、テスト担当、レビュー担当といった具合にエージェントが専門化されます。ここで重要なのが、エージェント同士がどのようにコミュニケーションをとるかです。
自然言語のチャットだけでやり取りをすると、情報が欠落したり、現在のプロジェクト状態に関する認識がエージェント間でズレたりする危険性があります。そのため、テスト結果やソースコード、実行ログといった「客観的なコードの成果物」を共有のリポジトリとして扱い、それを介して同期を図る設計が求められます。コードという検証可能な事実を軸にすることで、複数エージェントの協調作業が安定して機能するようになります。
 図表3:マルチエージェントオーケストレーションとスケールアップの概要
図表3:マルチエージェントオーケストレーションとスケールアップの概要
主要な応用分野と将来の課題
コードを基盤としたエージェントシステムは、すでにさまざまな領域で実用化に向けた研究が進められています。
コーディングから科学的発見までの実例
論文では、主に以下の5つの応用分野が挙げられています。
- コーディングアシスタント: GitHubのイシュー解決や大規模なリポジトリの改修を自律的に行うシステム。
- GUI/OSエージェント: ブラウザやデスクトップ画面の情報を読み取り、人間のようにPCを操作するシステム。
- 身体的エージェント: ロボットが物理空間でタスクをこなすための制御コードを生成・実行するシステム。
- 科学的発見: 仮説の立案からシミュレーション、データ分析までの一連の実験プロセスを自動化するシステム。
- パーソナライゼーション: ユーザーの嗜好をコードや構造化データとして記録し、推薦アルゴリズムを継続的に改善するシステム。
ハーネスの評価と安全性の確保
有望な成果が報告されている一方で、解決すべき課題も残されています。従来のAI評価は「最終的にテストを通過したか」に偏りがちですが、今後はエージェントがどれだけ効率よくツールを使い、エラーから復帰し、安全な権限範囲内で動作したかを測る「ハーネスレベルの評価指標」が必要です。
また、システムが自律的にコードを実行するため、重大なシステム変更や外部ネットワークへのアクセスには、必ず人間の承認(ヒューマン・イン・ザ・ループ)を挟むような権限管理の仕組みが不可欠です。
まとめ
AIエージェントにおける「コード」は、人間が読むための成果物から、AIが思考し、行動し、世界を認識するための基盤システム(ハーネス)へと役割を変えました。推論の検証からPEVループの確立、そしてマルチエージェントの連携に至るまで、コードの「実行可能」「検証可能」「状態保持」という性質が、AIの自律性を大きく支えています。
今後、エージェントがより複雑で現実的なタスクをこなすようになるにつれ、この「コード・アズ・ハーネス」の設計とエンジニアリングの重要性はさらに高まっていくでしょう。
生成AIの導入や活用にお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: