LLMのセキュリティ、アーキテクチャが鍵?Function CallingとMCPの脆弱性比較から学ぶ実践的対策
公開日
大規模言語モデル(LLM)を搭載した自律型エージェントは、単なるテキスト生成ツールから、外部システムと連携し複雑なタスクを自動化する存在へと進化を遂げています。しかし、その高機能化と同時に、これまでとは質の異なるセキュリティリスクが浮上しており、開発者やセキュリティ専門家にとって新たな課題となっています。
本記事では、LLMエージェントの2つの主要なアーキテクチャである「Function Calling」と「Model Context Protocol (MCP)」の脆弱性を詳細に比較評価した最新の研究論文「Bridging AI and Software Security: A Comparative Vulnerability Assessment of LLM Agent Deployment Paradigms」の内容に基づき、アーキテクチャの選択がセキュリティに与える影響と、私たちが取るべき対策について深く掘り下げていきます。
調査の概要:2つの主要アーキテクチャと攻撃シナリオ
この研究では、LLMエージェントのセキュリティを評価するため、市場で広く採用されている2つの異なるアーキテクチャパラダイムを対象としました。
- Function Calling: OpenAIやAnthropicなどが提供する、ツール定義や実行ロジックがエージェント内に集約された中央集権的なモデルです。
- Model Context Protocol (MCP): 2025年初頭に標準化された、ツール実行をエージェント本体から分離する分散型のクライアントサーバーモデルです。
研究チームは、これら2つのアーキテクチャに対し、AI固有の脅威である「プロンプトインジェクション」や、伝統的な「JSONインジェクション」「サービス拒否(DoS)攻撃」など、様々な攻撃を仕掛けました。さらに、攻撃の巧妙さを「単純攻撃」「複合攻撃(複数の技術を組み合わせる)」「連鎖攻撃(複数のシステムコンポーネントを段階的に侵害する)」の3段階に分類し、合計3,250ものシナリオでテストを行いました。
明らかになった脆弱性の違い:Function Calling vs MCP
実験の結果、アーキテクチャの設計思想が脆弱性の種類や攻撃の成功率に根本的な違いを生むことが明らかになりました。
全体的な攻撃成功率ではFunction Callingに課題
調査によると、全体的な攻撃成功率(ASR)はFunction Callingが73.5%であったのに対し、MCPは62.59%と、Function Callingの方が脆弱性が高い結果となりました。
図表1 Attack Success Rate Comparison - Function Calling vs Model Context Protocol
図1が示すように、Function Callingはツール連携が密結合であるため、APIパラメータの奪取やJSONインジェクションといった「システム中心の攻撃」に弱い傾向があります。一度侵入を許すと、被害が内部全体に広がりやすい構造と言えるでしょう。
MCPはLLM中心の攻撃に弱い
一方で、MCPは「LLM中心の攻撃」に対する成功率が68.28%と高く、Function Callingの59%を上回りました。これは、MCPの分散型アーキテクチャが持つ、コンテキストが豊富な通信プロトコル自体を悪用され、プロンプトインジェクションなどの攻撃を受けやすいことを示唆しています。アーキテクチャの分離が、逆に新たな攻撃対象領域を生み出してしまったのです。
攻撃が複雑化するほど脅威は増大する
本研究で最も注目すべきは、攻撃の複雑性が増すことによる脅威の増大です。単一の脆弱性を突く単純な攻撃の成功率は約50%でしたが、複数の手法を組み合わせた「連鎖攻撃」になると、その成功率は驚異的な 91〜96% にまで跳ね上がりました。
図表2 Chained Attack Progression - Attack Success Rate by Chain Depth
図2は、攻撃のステップ数(Attack Chain Depth)が増えるにつれて、攻撃成功率(ASR%)が急激に上昇する様子を示しています。特にFunction Calling(FC Azure (OpenAI)など)では、5ステップの連鎖攻撃で成功率が95%に達しており、中央集権型アーキテクチャのリスクが浮き彫りになりました。この結果は、個別の脆弱性対策だけでなく、攻撃者がたどる一連の経路(攻撃チェーン)をいかにして断ち切るか、という視点の重要性を示しています。
高度なAIはより危険?推論能力と脆弱性の逆説的関係
興味深いことに、本研究では「高度な推論能力を持つモデルほど、最終的な脆弱性が高まる」という逆説的な関係が明らかになりました。
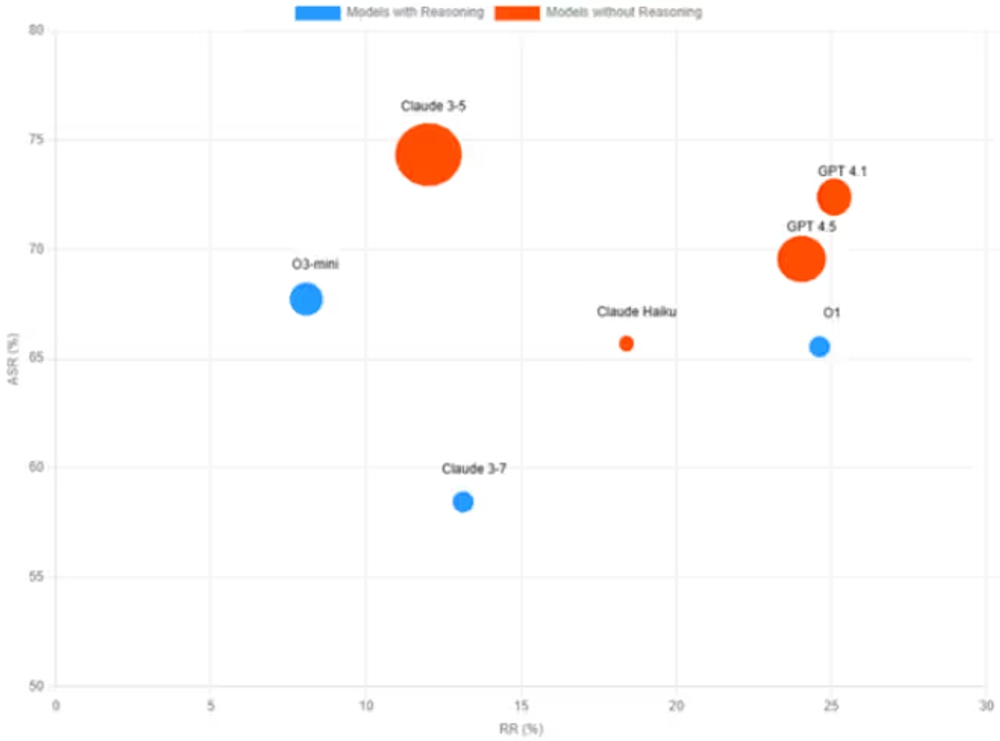
図表3 Model Security Profiles - Exploitability vs Defense Capability
図3は、各モデルの防御能力(RR% - 拒否率)と悪用可能性(ASR% - 攻撃成功率)の分布を示しています。Claude 3-5やGPT-4.1といった高性能モデルは、不正な要求を拒否する能力(RR)は高いものの、一度防御を突破されると攻撃が成功してしまう確率(ASR)もまた高い傾向にありました。これは、モデルの高度な能力が、攻撃者によって悪用され、より巧妙な攻撃を可能にしてしまう可能性を示唆しています。
結論:LLMエージェントのセキュリティはアーキテクチャ設計から
この研究は、LLMエージェントのセキュリティが、後付けのパッチや個別の対策だけで確保できるものではなく、開発初期のアーキテクチャ設計に根本的に依存するという重要な事実を突きつけています。
開発者やセキュリティ担当者は、以下の点を考慮する必要があります。
- アーキテクチャレベルの脅威モデリング: アプリケーションの設計段階で、Function CallingとMCPのどちらを採用するかが、その後のセキュリティ体制を大きく左右します。それぞれのトレードオフを理解し、自社のユースケースに合った選択をすることが不可欠です。
- 攻撃チェーンを断ち切る防御戦略: 単一の脆弱性を塞ぐだけでは不十分です。入力から処理、実行、出力に至るまでの一連のプロセスを監視し、攻撃の連鎖を断ち切る「チェーンブレーキング」の考え方を取り入れた多層的な防御が求められます。
- 統合的なセキュリティ評価: モデルの推論能力とアーキテクチャの特性は、相互に影響し合います。モデルの選定とアーキテクチャの構成を個別に最適化するのではなく、両者を組み合わせた状態での総合的な脆弱性評価を実施する必要があります。
LLMエージェントの活用が本格化する中で、その利便性の裏に潜むリスクを正確に理解し、設計段階からセキュリティを組み込む「セキュリティ・バイ・デザイン」のアプローチが、これまで以上に重要になることは間違いありません。
Webサービスや社内のセキュリティにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: