LLMはコードレビューをどう変える?最新研究が示すAI支援の最適なかたちとは
公開日
ソフトウェア開発の現場では、LLM(大規模言語モデル)の活用が急速に進んでおり、コーディングの自動化や効率化に大きく貢献しています。しかし、開発プロセスの中でも特に時間と認知コストを要する「コードレビュー」の領域では、LLMをどのように活用すれば最も効果的なのか、まだ明確な答えは出ていませんでした。
本記事では、この問いに迫るチャルマース工科大学とヨーテボリ大学による修士論文「Rethinking Code Review Workflows with LLM Assistance」に基づき、開発者の生産性を最大化するAIとの協業スタイルと、その導入を成功させるための条件について詳しく解説します。
研究で明らかになった、現代コードレビューの3つの課題
この研究は、スウェーデンのソフトウェア開発企業WirelessCarで働く開発者を対象とした、現場での観察(フィールドスタディ)と実際のツールを用いた実験(フィールド実験)に基づいています。まず、研究の第一段階として、現代のコードレビュープロセスが抱える、根深くも普遍的な課題が浮き彫りになりました。
レビュアーの不在とレビューの遅延
多くの開発チームでは、誰がレビューを行うかという明確な割り当てルールがなく、プルリクエスト(PR)が出されても「誰かがやってくれるだろう」という状況に陥りがちです。その結果、PRが長期間放置され、開発者はSlackなどで個別に催促する必要があり、コミュニケーションコストの増大と開発サイクルの遅延を引き起こしていました。
図表1:WirelessCarにおける典型的なコードレビューワークフロー

大規模なプルリクエスト(PR)の形骸化
新機能の実装とリファクタリングが混在した大規模なPRは、レビュワーにとって大きな精神的負担となります。すべての変更点を詳細に把握することが困難なため、レビューが表面的になり、重要な欠陥が見逃されるリスクが高まります。ある参加者は「PRが大きすぎると、誰も手をつけたがらない」と証言しており、レビュープロセスの形骸化が懸念されます。
頻繁なコンテキストスイッチによる生産性の低下
開発者は、集中して取り組んでいる自身のコーディング作業を中断し、全く異なる文脈のコードレビューを行わなければなりません。この「コンテキストスイッチ」は、レビュワーに大きな認知負荷をかけます。研究に参加したある開発者は「たとえ3分の作業でも、コンテキストスイッチには20分のロスが生じる」と述べており、生産性への深刻な影響が示唆されています。
LLMによるコードレビュー支援:2つのアプローチを比較検証
これらの課題を解決するため、研究チームはLLMを活用したコードレビュー支援ツールを開発し、フィールド実験を行いました。実験では、AIの介入方法が異なる2つのモードを用意し、どちらが開発者にとってより有用かを検証しました。
モードA「Co-Reviewer」:AIが積極的にレビューを主導
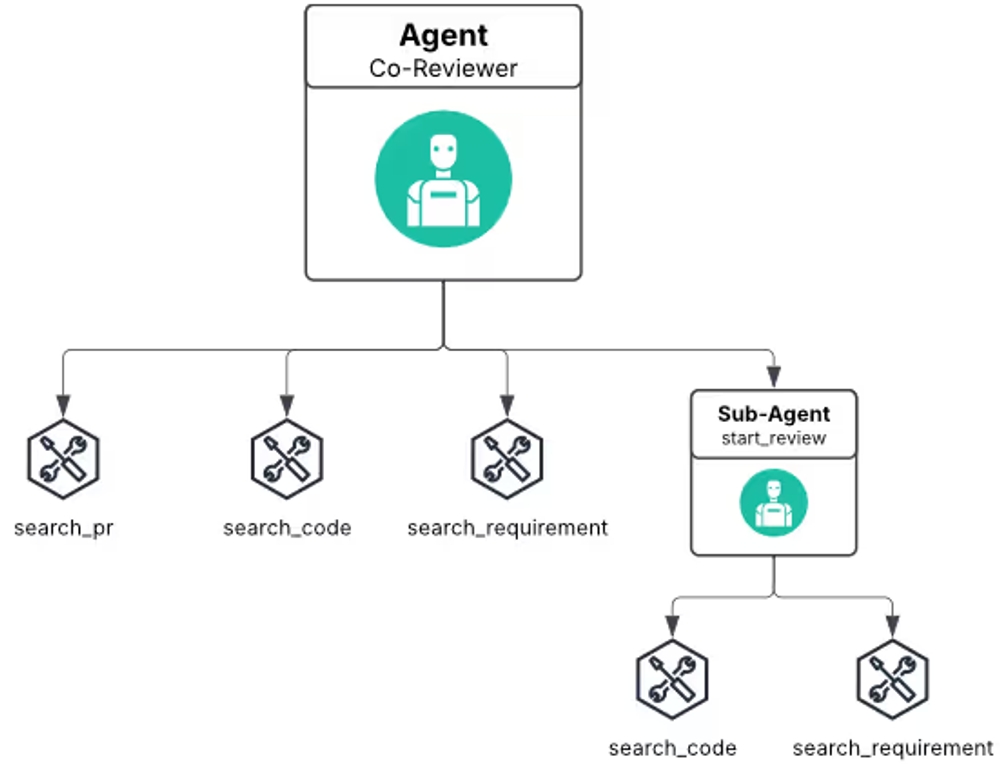
このモードでは、開発者がレビューを開始すると、まずAIがPRの概要、主要な変更点、潜在的なリスクや懸念事項をまとめたレポートを自動的に生成します。レビュワーはこの初期レポートを手がかりに、効率的にレビューを進めることができます。AIがレビュワーの「同僚(Co-Reviewer)」として、積極的に情報を提供するスタイルです。
図表2:Co-Reviewerモードのエージェントツール構造
モードB「Interactive Assistant」:開発者の質問にAIが応答
一方、こちらのモードではAIは基本的に受動的です。AIが自ら情報を提供することはなく、開発者が特定のコードについて質問したり、アーキテクチャに関する説明を求めたりした時にだけ応答します。レビュワーが自身のペースと判断でレビューを進め、必要な時にだけAIを「対話型アシスタント(Interactive Assistant)」として利用するスタイルです。
図表3:Interactive Assistantモードのエージェントツール構造
開発者が本当に求めていたのはどちらか?実験結果が示す最適な協業スタイル
実験の結果、多くの開発者は特定の条件下で明確な好みを示しました。これは、LLM支援を導入する上で非常に重要な示唆を与えてくれます。
多数派が支持した「Co-Reviewer(モードA)」、その理由は?
10人の参加者のうち6人が、明確にモードAを支持しました。その最大の理由は、レビュー開始時に提供される「概要の把握しやすさ」です。特に、自分が詳しくないコードベースや、変更点が数百ファイルに及ぶような大規模なPRをレビューする際に、AIが生成する初期レポートが「どこから手をつければ良いか」という道しるべとなり、認知的な負担を大幅に軽減することが分かりました。
また、チームに新しく参加した開発者がコードベースを学ぶための教育ツールとしても非常に有効である、という意見も多く聞かれました。
「Interactive Assistant(モードB)」が輝く特定のシナリオ
一方で、モードBを好む開発者もいました。彼らに共通していたのは、レビュー対象のコードベースに精通している、またはリスクの高い重要な変更をレビューしている、という点です。このような専門家は、AIの能動的な介入を「ノイズ」と感じることがあり、レビューの主導権を完全に自身で握りたいと考えます。必要な情報だけをピンポイントで引き出せるモードBは、彼らにとってより制御しやすく、効率的な選択肢となりました。
結論:画一的な支援ではなく、状況に応じた使い分けが鍵
この結果が示すのは、どちらか一方のモードが絶対的に優れているわけではない、ということです。最適な支援の形は、「レビュー対象の複雑さ」 と 「レビュワーの習熟度」 という2つの軸によって決まります。
- 不慣れなコード、大規模なPR → モードA(Co-Reviewer)が有効
- 習熟したコード、重要なPR → モードB(Interactive Assistant)が有効
効果的なLLM支援ツールは、開発者がこの2つのモードを柔軟に切り替えられる、あるいはハイブリッドに利用できる機能を持つべきだと言えるでしょう。
LLMコードレビュー支援を成功に導く3つの条件
さらに、この研究ではモードの種類に関わらず、LLM支援ツールが開発者に受け入れられるために不可欠な3つの条件が明らかになりました。
条件1:信頼性 - 正確なフィードバックが大前提
実験中、AIが時に不正確な指摘をしたり、存在しない問題を「ハルシネーション(もっともらしい嘘)」として生成したりする場面がありました。開発者はAIの提案を鵜呑みにせず、常に批判的な視点で検証していました。一度でも「このツールは信頼できない」という認識が広まると、どんなに高機能でも使われなくなってしまいます。正確で信頼性の高いフィードバックこそが、全ての土台となります。
条件2:統合性 - 既存ワークフローへのシームレスな組み込み
開発者は、レビューのために見慣れない新しいUIに切り替えることを好みません。理想的なのは、普段から使い慣れているGitHubのPR画面や、Slackの通知スレッド、あるいはVSCodeなどのIDEに、AIの機能がシームレスに統合されていることです。また、質問してから応答までに数分待たされるような体験は、レビューのフローを著しく妨げます。高速なレスポンスと既存ツールとの深い統合が、導入成功の鍵を握ります。
条件3:文脈理解 - コードと要求仕様を深く紐づける能力
最も価値のあるAI支援は、単に変更されたコードの断片を静的に分析するだけではありません。そのPRが解決しようとしているビジネス上の要求(Jiraチケットの内容など)や、リポジトリ全体のアーキテクチャ、過去の変更履歴といった、より広い「文脈」を理解した上でフィードバックを提供することです。この研究で用いられたツールは、RAG(Retrieval-Augmented Generation)技術によってこれらの外部情報を参照しましたが、文脈理解の精度向上は、今後の重要な課題です。
まとめ:LLMはコードレビューの代替ではなく「パートナー」へ
本研究は、LLMがコードレビューのプロセスに大きな変革をもたらす可能性を明確に示しました。重要なのは、LLMが人間のレビュワーを「代替」するのではなく、認知的な負担を軽減し、見落としがちな問題を指摘し、より本質的な設計やアーキテクチャの議論に集中できるよう支援する強力な「パートナー」となりうるという点です。
事前に概要を示す「Co-Reviewer」と、オンデマンドで応答する「Interactive Assistant」。この2つの顔を状況に応じて使い分ける柔軟性を持ち、信頼性、統合性、文脈理解能力を備えたLLMツールこそが、未来の開発現場において、コードの品質と開発者の生産性を飛躍的に向上させる原動力となるでしょう。
開発生産性やチームビルディングにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: