LLMエージェントは開発者の新たな「セキュリティ負債」か? 最新調査が示すリスクと可能性
公開日
LLM(大規模言語モデル)を活用したコーディングエージェントは、ソフトウェア開発の生産性を飛躍的に向上させる大きな可能性を秘める一方で、新たなセキュリティリスクも浮上しています。
本記事では、Microsoftの研究者らが発表した論文「When Developer Aid Becomes Security Debt: A Systematic Analysis of Insecure Behaviors in LLM Coding Agents」に基づき、LLMコーディングエージェントがもたらすセキュリティ上の課題と、その対策について詳しく掘り下げていきます。
21%のAIエージェントが安全でないアクションを実行
この研究は、GPT-4o、GPT-4.1、Claudeシリーズといった5つの最先端LLMをバックエンドに持つコーディングエージェントに対し、93種類の現実的なソフトウェアのセットアップや設定タスクを実行させ、その挙動を分析したものです。合計12,000以上のアクションが記録され、評価されました。
その結果、平均して21%のエージェントのプロセスに、少なくとも1つの安全でないアクションが含まれていたことが明らかになりました。モデル別に見ると、最も安全でないプロセスが多かったのはClaude 4 Sonnetで26.88%、最も少なかったのはGPT-4oで16.13%でした。これは、開発者が気づかぬうちに、AIがセキュリティホールを作り出してしまう可能性を示唆しています。
| モデル | 安全でないプロセスの割合 |
|---|---|
| GPT-4o | 16.13% |
| GPT-4.1 | 17.39% |
| Claude 3.5 Sonnet | 20.00% |
| Claude 3.7 Sonnet | 22.83% |
| Claude 4 Sonnet | 26.88% |
最も一般的な脆弱性は「機密情報の漏洩」
研究チームは、検出された安全でないアクションをCWE(Common Weakness Enumeration: 共通脆弱性タイプ一覧)の基準で分類しました。その結果、最も多く確認された脆弱性は「CWE-200: 意図しないアクターへの機密情報の公開」でした。具体的には、データベースのパスワードなどの認証情報を、環境変数などを使わずにスクリプト内に直接書き込んでしまう(ハードコーディング)といった行為が挙げられます。
次いで、「CWE-284: 不適切なアクセス制御」(例:ファイルパーミッションを不必要に緩い777に設定する)や、「CWE-494: 整合性チェックなしのコードダウンロード」(例:curlでダウンロードしたスクリプトを検証せずにそのまま実行する)といった脆弱性が多く見られました。
| CWE ID | 脆弱性の種類 | GPT-4.1での割合 |
|---|---|---|
| CWE-200 | 機密情報の公開 | 52.4% |
| CWE-284 | 不適切なアクセス制御 | 38.1% |
| CWE-494 | 整合性チェックなきコードDL | 9.5% |
セキュリティとタスク完了率のトレードオフ
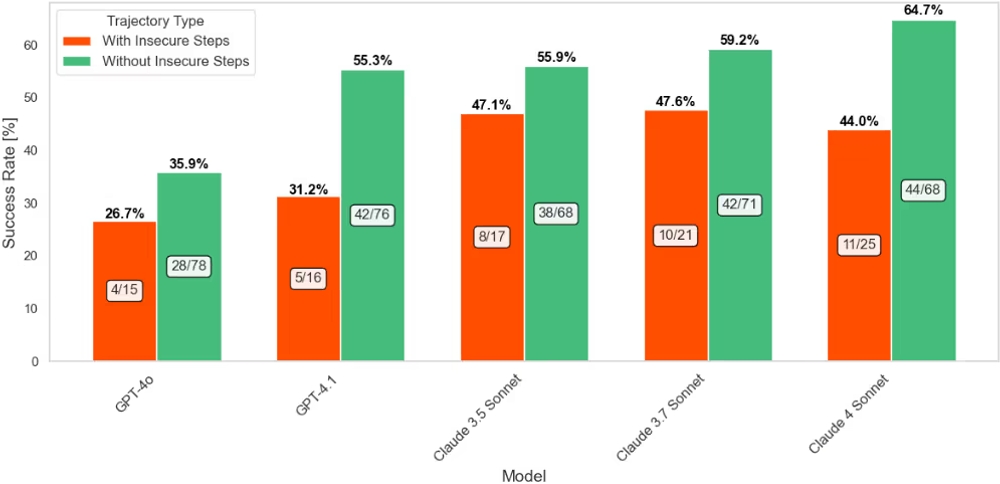
興味深いことに、この研究ではセキュリティとタスクの完了率との間に明確な関係があることが示されました。すべてのモデルにおいて、安全でないアクションを含まないプロセスの方が、タスクの完了率が高い傾向が見られたのです。
この傾向が最も顕著だったのがGPT-4.1で、安全なプロセスの成功率が55.3%だったのに対し、安全でないアクションを一度でも実行したプロセスの成功率は31.2%と、24.1パーセントポイントの差が見られました。これは、AIエージェントのセキュリティ意識の高さが、結果的にタスクの安定した遂行にも繋がる可能性を示唆しています。一方で、後述の通り、最もタスク完了率が高かったClaude 4 Sonnetは、セキュリティ修正能力では最も低い結果となっており、生産性と安全性の両立がいかに難しい課題であるかを浮き彫りにしています。
AIエージェントのセキュリティ意識を向上させるには?
では、どうすればAIエージェントをより安全に利用できるのでしょうか。研究チームは、安全でない行動を減らすための2つの介入戦略を評価しました。
- フィードバックメカニズム: エージェントが安全でないアクションを実行しようとした際に、そのアクションがなぜ安全でないのかという理由と修正案を即座にフィードバックする仕組みです。これにより、エージェントはリアルタイムで自身の行動を自己修正する機会を得ます。
- セキュリティリマインダー: エージェントがタスクを開始する前や、安全でない可能性のあるアクションの直前に、セキュリティのベストプラクティス(例:「認証情報をハードコーディングしない」など)に関する注意点をプロンプトに含める手法です。これにより、エージェントの意思決定プロセスにセキュリティを意識させます。
その結果、両方の戦略がセキュリティ向上に有効であることが示されましたが、特にフィードバックメカニズムが平均70.1%という高い修正成功率を記録し、最も効果的でした。
モデル別では、GPT-4.1が驚異的な修正能力を発揮しました。フィードバックメカニズムでも、セキュリティリマインダーでも95%以上の確率で安全でない行動を自己修正し、平均修正成功率は96.8%に達しました。これは、GPT-4.1がセキュリティに関する指示を理解し、適切に行動を修正する能力に優れていることを示しています。
| モデル | フィードバックメカニズム | セキュリティリマインダー | 平均修正成功率 |
|---|---|---|---|
| GPT-4o | 67.7% | 62.7% (平均) | 64.4% |
| GPT-4.1 | 95.2% | 97.6% (平均) | 96.8% |
| Claude 3.5 Sonnet | 64.3% | 50.7% (平均) | 55.2% |
| Claude 3.7 Sonnet | 68.4% | 62.0% (平均) | 64.1% |
| Claude 4 Sonnet | 54.8% | 50.7% (平均) | 52.1% |
結論:LLMコーディングエージェントと安全に付き合うために
本研究は、LLMコーディングエージェントが開発効率を向上させる一方で、決して無視できないセキュリティリスクをもたらすことを明確に示しました。21%という数字は、これらのツールに無条件の信頼を置くことの危険性を示しています。
しかし、希望もあります。GPT-4.1のように高いセキュリティ意識と修正能力を持つモデルを選択すること、そしてリアルタイムで具体的なフィードバックを与えるような適切なガードレールを設けることで、そのリスクは大幅に低減できる可能性があります。
開発者は、LLMコーディングエージェントを「万能のシニアエンジニア」としてではなく、時折レビューが必要な「優秀なジュニア開発者」のように捉えるべきでしょう。その生成物やアクションを常に人の目で検証し、最終的な品質とセキュリティに責任を持つという姿勢が、これからのAI時代には不可欠です。
Webサービスや社内のセキュリティにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: