LLM×ミューテーションテストは有効か?Metaの大規模実験で明らかに
公開日
本記事では、Meta社が発表した論文「Mutation-Guided LLM-based Test Generation at Meta」(2024)に基づき、LLM(大規模言語モデル)とミューテーションテストを組み合わせた新しいテスト生成手法の有効性を検証します。同社の実験結果から、LLM×ミューテーションテストの可能性と、今後のソフトウェアテスト技術の進化について考察します。
近年、LLMの発展は目覚ましく、ソフトウェア開発の様々な場面で活用が進んでいます。特に、ソースコードや自然言語による指示に基づき、テストコードを自動生成できるLLMは、テスト作成のコスト削減や時間短縮をもたらす技術として注目されています。しかし、LLMによるテスト生成には、既存のテストスイートや人が書いたコードと似たようなものになりやすく、カバレッジ(コード網羅率)は高くても、特定の種類のバグ(例えば、境界値付近のバグや、複雑な条件分岐に関わるバグ)を見逃してしまう可能性があるという課題があります。
ミューテーションテストとは?:LLMの課題を解決する鍵
そこで注目したいのが、ミューテーションテストという手法です。ミューテーションテストとは、プログラムに人為的に小さな変更(ミュータント)を埋め込み、その変更を検出できるテストケースを作成・評価する手法です。ミュータントは、現実のバグを模倣したものであり、例えば、
- 比較演算子の不等号の向きを変える(
>を<に変える) - 論理演算子を入れ替える(
&&を||に変える) - 変数の値をわずかに変化させる
といった変更が加えられます。ミュータントを検出できるテストケースは、潜在的なバグを発見できる可能性が高いと考えられます。つまり、ミューテーションテストは、テストスイートがどれだけ効果的にバグを検出できるかを評価する指標となるのです。
なぜLLMとミューテーションテストを組み合わせるのか?
LLMによるテスト生成は、「カバレッジは高いが、多様なバグを検出できない可能性がある」という課題を抱えています。一方、ミューテーションテストは、テストスイートの品質評価に優れ、多様なバグを検出するテストケースの必要性を示唆してくれます。この2つを組み合わせることで、
- LLMの自動生成能力を活用しつつ、ミューテーションテストによってテストの質と多様性を高める
- より現実に即した様々なバグを想定したテストケースを効率的に作成できる
- カバレッジだけでは測れない、ソフトウェアの潜在的な脆弱性を発見できる
といった効果が期待できます。
Metaの実験:LLMとミューテーションテストの大規模検証
実験の目的と対象プラットフォーム
Metaは、LLMとミューテーションテストを組み合わせたテスト生成手法の有効性を検証するため、同社の7つの主要なプラットフォーム(WhatsApp, Messenger, Facebook Feed, Instagramなど)を対象に、大規模な実験を行いました。この実験の目的は、
- LLMを用いて、特定の問題領域(この実験ではプライバシー問題)に特化したミュータントを生成できるか
- 生成されたミュータントを検出するテストケースをLLMで自動生成できるか
- 生成されたテストケースが、実際にエンジニアにとって有用であるか
を検証することにありました。
実験システム「ACH」の概要
実験では、「ACH (Automated Compliance Hardener)」と呼ばれるシステムが使用されました。ACHは、特定の問題領域(論文ではプライバシー問題に焦点)に関連するミュータントを生成し、それらのミュータントを検出するテストケースを作成することで、ソフトウェアの堅牢性を高めることを目的としています。
ACHシステムのアーキテクチャ
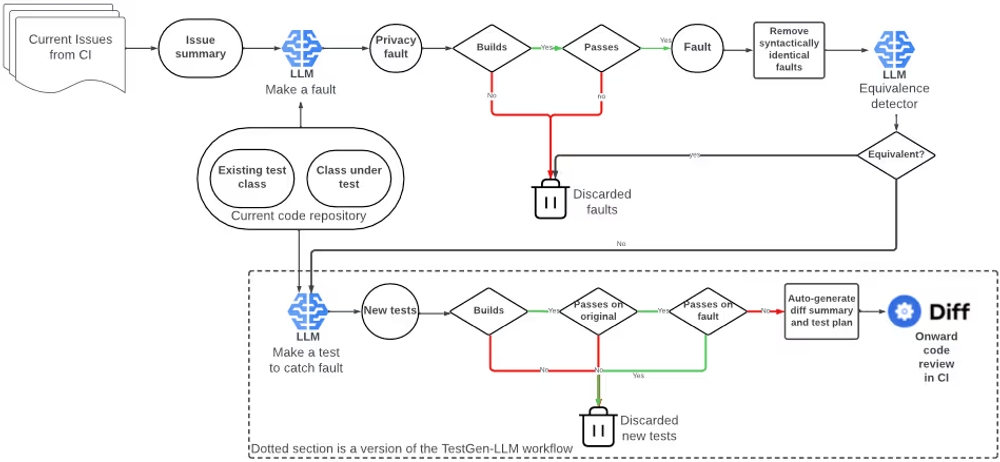
ACHの主要コンポーネント:3つのLLMエージェント
ACHは、上記の図に示すように、主に3つのLLMエージェントによって構成されています。
- 「Make a fault」エージェント:
- 役割: 既存のコードと、対象とする問題領域に関する情報(論文ではプライバシー侵害に関する過去のバグ情報など)を入力として、問題を含むコード(ミュータント)を生成します。
- 動作: 例えば、過去のプライバシー侵害バグの概要を参考に、類似のバグを再現するようなコード変更を既存のコードに加えます。
- 「Make a test to catch fault」エージェント:
- 役割: 元のコードと、「Make a fault」エージェントが生成したミュータントを入力として、ミュータントを検出するテストケースを生成します。
- 動作: ミュータントによって生じるプログラムの挙動の変化を捉え、その変化を検出できるようなアサーション(期待される結果の記述。例えば、「この入力に対して、この出力が返されるべき」という検証)を含むテストケースを生成します。
- 「Equivalence detector」エージェント:
- 役割: 生成されたミュータントが等価ミュータント(元のプログラムと意味的に同じミュータント)かどうかを判定します。
- 動作: 元のコードとミュータントの振る舞いを比較し、両者に違いがないかをLLMが判断します。
等価ミュータント問題とその対策
ミューテーションテストにおける課題の一つに、「等価ミュータント」の存在があります。等価ミュータントとは、元のプログラムと意味的に同じ(つまりバグではない)ミュータントのことです。等価ミュータントは、テストケースを生成しても意味がないため、効率的なテスト生成の妨げとなります。
ACHではこの問題に対処するため、
- LLMによる判定(「Equivalence detector」エージェント)
- 構文的に同一なミュータントの自動除去
- コメントのみが変更されたミュータントの検出
といった対策を組み合わせました。特に、LLMを用いた等価ミュータント判定は、従来の手法では困難だった、文脈を考慮した高度な判定を可能にします。
生成されたミュータントのタイプ
LLMは具体的にどのようなミュータントを生成するのでしょうか?下記の表は、生成されたミュータントのタイプ分類とその内訳を示しています。
生成されたミュータントのタイプ分類と内訳
| プラットフォーム | 合計ミュータント数 | 等価ミュータント(人手確認) | 等価ミュータント(LLM判定) | 人手による判断が困難 | コード削除 | コード挿入 | 削除+挿入 | 誤解を招くコメント | その他 |
|---|---|---|---|---|---|---|---|---|---|
| Messenger | 91 | 38 (42%) | 27 (30%) | 2 (2%) | 23 (25%) | 32 (35%) | 19 (21%) | 11 (12%) | 6 (7%) |
| Wearables | 101 | 32 (32%) | 11 (12%) | 3 (3%) | 26 (26%) | 24 (24%) | 20 (20%) | 24 (24%) | 7 (7%) |
| 99 | 30 (30%) | 16 (16%) | 3 (3%) | 29 (29%) | 26 (26%) | 16 (16%) | 26 (26%) | 2 (2%) | |
| 90 | 37 (41%) | 12 (13%) | 2 (2%) | 27 (30%) | 14 (16%) | 11 (12%) | 32 (36%) | 6 (7%) | |
| 全体 | 381 | 137 (36%) | 66 (17%) | 10 (2.6%) | 105 (28%) | 96 (25%) | 66 (17%) | 93 (24%) | 21 (6%) |
LLMはコードの削除、挿入といった典型的な変更だけでなく、「誤解を招くコメント」のような、LLM特有のミュータントも生成することが分かります。
等価ミュータント検出エージェントの性能
ACHの「Equivalence detector」エージェントは、どの程度正確に等価ミュータントを検出できるのでしょうか?下記の表は、その性能を詳細に示しています。
等価ミュータント検出エージェントの性能詳細
| 正解(真陽性) | 誤判定(偽陽性) | 正解(真陰性) | 誤判定(偽陰性) | 精度 | 再現率 | |
|---|---|---|---|---|---|---|
| 不確実な場合を除外 | 56 | 2 | 205 | 72 | 0.97 | 0.44 |
| 不確実な場合を等価と判定 | 65 | 17 | 205 | 72 | 0.79 | 0.47 |
| 構文的に同一なら等価と判定 | 161 | 17 | 205 | 72 | 0.90 | 0.69 |
| コメント削除後、構文的に同一なら等価と判定 | 183 | 9 | 251 | 8 | 0.95 | 0.96 |
単純なLLM判定だけでなく、前処理(構文的に同一なミュータントの除去や、コメント削除)を組み合わせることで、非常に高い精度(0.95)と再現率(0.96)で等価ミュータントを検出できることが分かります。これは言い換えれば、LLMが生成したミュータントのうち、本当に意味のある(テストケースを生成する価値のある)ミュータントを、高い精度で選び出せることを意味します。
Metaの実験結果:エンジニア評価とTestGen-LLMとの比較
生成されたミュータントとテストケース
実験の結果、Metaの7つのプラットフォーム (WhatsApp, Messenger, Facebook Feed, Instagram, Aloha, Wearables, Cross-app, Oculus) において、合計10,795のクラスから9,095個のミュータントが生成されました。そのうち、4,660個が非等価(元のプログラムと意味的に異なる)と判定され、最終的に571個のテストケースが生成されました。
エンジニアによるテストの評価
生成されたテストケースは、Metaのエンジニアによってレビューされ、有用性とプライバシー関連性が評価されました。評価は、初期トライアルと、より大規模なtest-a-thonsの2段階で行われました。
初期トライアルでは、30個のテストケースがレビューされ、そのうち23個 (77%) が「そのまま受け入れ可能」、4個 (13%) が「軽微な修正で受け入れ可能」と判定されました。
test-a-thonsでは、WhatsAppとMessengerを対象に、合計191個のテストケースがレビューされました。その結果、全体の73%にあたる140個のテストケースが受け入れられました。また、プライバシーとの関連性については、全体の36%にあたるテストケースが「プライバシーに関連する可能性がある」または「プライバシーに確実に関連する」と評価されました。
これらの結果から、ACHが生成するテストケースは
- 実用的な価値を持つ
- 特定の問題領域(この場合はプライバシー)に対して有効である
ことが示されています。
TestGen-LLMとの比較:ミューテーションテストの優位性
論文では、ACHと、カバレッジ(コード網羅率)の向上を目的としたLLMベースのテスト生成ツール「TestGen-LLM」との比較も行われています。TestGen-LLMは、既存のコードを解析し、カバレッジが低い部分を重点的にテストするコードを、探索ベースのアルゴリズムを用いて生成するツールです。
ACHとTestGen-LLMのミュータント検出率とカバレッジの比較
| プラットフォーム | 非等価ミュータント数 | ミュータント検出テスト数(%) | カバレッジ非向上ミュータント検出テスト数(%) | TestGen-LLMミュータント検出率 |
|---|---|---|---|---|
| Facebook Feed | 133 | 15(11%) | 9(60%) | 3.7% |
| Messenger | 1,155 | 196(17%) | 84(43%) | 2.4% |
| 687 | 122(18%) | 77(55%) | 3.1% | |
| Aloha | 74 | 9(12%) | 4(44%) | 1.2% |
| Wearables | 1,007 | 45(4%) | 32(71%) | 2.5% |
| Cross-app | 275 | 35(13%) | 20(57%) | 2.7% |
| Oculus | 121 | 14(12%) | 3(21%) | 6.1% |
| 445 | 135(30%) | 48(36%) | 4.2% | |
| 合計 | 3,897 | 571(15%) | 277(49%) | 2.4% |
その結果、ACHはTestGen-LLMよりもはるかに多くのミュータントを検出できることが明らかになりました(ACH: 15%, TestGen-LLM: 2.4%)。また、興味深いことに、ACHが生成したテストケースの約半数(49%)は、カバレッジを向上させないにも関わらず、ミュータントを検出することに成功していました。このことは、カバレッジだけを指標としたテストでは、潜在的なバグを見逃してしまう可能性があることを示唆しており、ミューテーションテストの重要性を改めて裏付けています。
まとめと今後の展望:LLM×ミューテーションテストの可能性
Metaの論文は、LLMとミューテーションテストを組み合わせたテスト生成手法が、大規模なソフトウェア開発において有効であることを実証しました。特に、ACHが生成するテストケースは、エンジニアによる受け入れ率が高く、特定の問題領域(プライバシー)に対して有効であることが示されました。また、等価ミュータント問題への対策や、カバレッジだけにとらわれないテストの重要性など、今後のテスト生成技術の発展に繋がる貴重な知見を提供しています。
LLMとミューテーションテストの組み合わせは、まだ発展途上の技術ですが、
- より多様なバグを検出できる
- テストの質を向上させる
- ソフトウェアの信頼性を高める
といった点で、大きな可能性を秘めています。今後の研究開発においては、以下のような点が重要な課題となるでしょう。
- ミュータント生成の多様性向上: より現実に近い、多様なミュータントを生成できるよう、LLMをさらに改良する。
- 等価ミュータント検出の精度向上: 等価ミュータント検出の精度をさらに高め、テスト生成の効率を向上させる。
- 異なるプログラミング言語や問題領域への適用: 今回の実験はKotlin言語とプライバシー問題に焦点を当てたものでしたが、他の言語や問題領域(セキュリティ、パフォーマンスなど)にも適用範囲を広げる。
- テスト生成以外の応用: LLMをテスト生成だけでなく、テストの優先順位付け、テスト結果の分析、さらにはバグの自動修正など、より広範なソフトウェア開発プロセスに応用する。
これらの課題に取り組むことで、LLMとミューテーションテストは、ソフトウェアテストの自動化をさらに進化させ、高品質なソフトウェア開発に大きく貢献することが期待されます。
開発生産性やチームビルディングにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: