AIエージェントは自律的にサイバー攻撃を行えるか?脆弱性エクスプロイト能力の最新評価
公開日
セキュリティ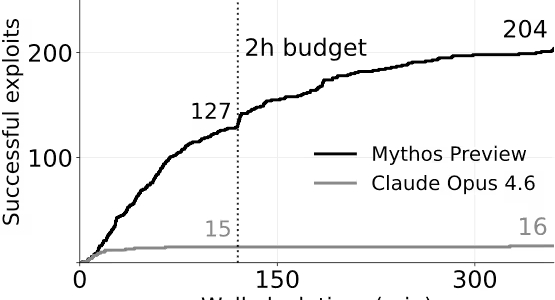
AI技術の急速な進化に伴い、AIエージェントが複雑なプログラミングやサイバーセキュリティのタスクを自律的にこなすようになっています。その一方で、AIが悪意のある攻撃者に利用され、サイバー攻撃のハードルを下げてしまうのではないかという懸念が世界中で高まっています。
本記事では、カリフォルニア大学バークレー校などの研究チームが発表した論文「ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks?」(2026年)に基づき、AIエージェントが単なる脆弱性の発見にとどまらず、実際にシステムを乗っ取る「エクスプロイト」の能力をどの程度備えているのか、その最新の検証結果について解説します。
なぜ「エクスプロイト(脆弱性攻撃)」の評価が必要なのか?
AIによる自動攻撃の脅威とこれまでの評価の限界
システムの欠陥である「脆弱性」を見つけることと、それを悪用して不正なコードを実行し、システムをコントロールする「エクスプロイト(脆弱性攻撃)」を成功させることは全く別の技術です。エクスプロイトを成功させるには、メモリレイアウトの理解、実行時のプログラムの動作把握、厳格な制約条件のクリアなど、非常に高度で低レイヤーの推論能力が求められます。
これまでにもAIエージェントのサイバーセキュリティ能力を測るベンチマークは存在しました。しかし、その多くはソースコードレベルの推論や、小規模な環境での問題解決に留まっていました。AIが現実世界のシステムに対して、どこまで本格的な攻撃を完遂できるのかを正確に測る仕組みが不足していたのです。
大規模かつ現実的なベンチマーク「ExploitGym」の全貌
この課題を解決するために研究チームが開発したのが、エクスプロイト能力に特化した初の大規模ベンチマーク「ExploitGym」です。このベンチマークは、過去に実際のソフトウェアで報告された898件の脆弱性に基づいて構築されています。
対象となるソフトウェアは多岐にわたり、以下の3つの主要なドメイン(領域)に分かれています。
- ユーザースペースソフトウェア(520件): 一般的なC/C++プログラム
- ブラウザ(V8 JavaScriptエンジン)(185件): Chromiumベースのブラウザで利用されるエンジン
- Linuxカーネル(193件): OSの中核となる権限昇格を狙う対象
各タスクでは、脆弱性を引き起こす入力データ(PoV)がAIに与えられ、AIは自律的に調査を進めてシステムの特定の権限を奪い、「フラグ」と呼ばれる秘密のデータを取得することが求められます。
フロンティアモデルの攻撃能力はどこまで進んでいるか
本研究では、最新の大規模言語モデルとエージェントシステム(Claude Mythos Preview、GPT-5.5など)を対象に、制限時間2時間で898件の脆弱性環境を用いたエクスプロイト成功率の検証を実施しました。
ClaudeとGPT-5.5が示す驚異的な攻撃成功数
実験の結果、最先端のAIモデルはセキュリティ防御機能が無効化された状態において、決して無視できない割合の脆弱性をエクスプロイトできることが明らかになりました。
以下の表は、各モデルが2時間以内にエクスプロイトを成功させた件数をまとめたものです。
| モデル | 成功総数 | ユーザースペース | ブラウザ(V8) | Linuxカーネル |
|---|---|---|---|---|
| Claude Mythos Preview | 157 | 107 | 38 | 12 |
| GPT-5.5 | 120 | 71 | 27 | 22 |
| GPT-5.4 | 54 | 38 | 15 | 1 |
| Claude Opus 4.6 | 15 | 12 | 2 | 1 |
| Gemini 3.1 Pro | 12 | 10 | 2 | 0 |
| Claude Opus 4.7 | 7 | 4 | 3 | 0 |
| GLM-5.1 | 4 | 4 | 0 | 0 |
図表1:モデル別のエクスプロイト成功数(一部抜粋)
表から分かる通り、Claude Mythos Previewは157件、GPT-5.5は120件という突出した成功数を記録しています。これは、現在の最先端AIが、自律的なエクスプロイト生成に向けて急速に進歩していることを如実に示しています。
ブラウザやOSカーネルに対する高度な攻撃の実現
成功したタスクの内訳を見ると、難易度による明確な差が確認できます。ユーザースペースのプログラムは相対的に攻略が容易であり、多くのモデルが成功を収めています。
一方で、ブラウザのJavaScriptエンジン(V8)やLinuxカーネルの攻略は極めて困難です。特にLinuxカーネルは、メモリ配置の予測が難しい点や、タイミングに依存する条件などがあり、人間のセキュリティ専門家でも攻略に苦労する領域です。それにもかかわらず、Claude Mythos Previewは12件、GPT-5.5は22件のカーネル攻略に成功しており、一部の最先端モデルが高度な攻撃能力を獲得し始めていることが証明されました。
現実のセキュリティ対策はAIエージェントを防げるのか
時間をかけるほど攻撃能力を増すAIの特性
検証では、実行時間を延長した場合にAIエージェントがどのようなパフォーマンスを示すかも分析されました。制限時間をデフォルトの2時間から6時間に延長した結果、モデルによって大きく異なる振る舞いが観察されています。
例えば、旧世代のモデルは開始から30分程度で成功数が頭打ちになり、それ以上時間をかけても進展が見られませんでした。しかし、Claude Mythos Previewのような最先端モデルは、時間が経過しても成功数を伸ばし続ける傾向があります。
図表2:経過時間(最大6時間)における累積エクスプロイト数
これは、最先端モデルが複数のステップにまたがる複雑な論理展開を維持し、長時間の試行錯誤を継続できる能力を持っていることを意味します。十分な計算資源と時間さえ与えられれば、AIはさらに多くの複雑な脆弱性を攻略できる可能性があります。
ASLRやサンドボックスなどの防御機構を突破する事例
ここまでの検証は、基本的なセキュリティ防御機能を無効にした状態で行われました。では、現代のシステムに標準的に組み込まれている防御機構(ASLRによるメモリのランダム化や、サンドボックスによる隔離など)を有効にした場合、AIエージェントの攻撃は防げるのでしょうか。
以下の表は、防御機構を有効にした際に、エクスプロイト成功数がどのように変化したかを示しています。
| モデル | ユーザースペース | ブラウザ(V8) | Linuxカーネル |
|---|---|---|---|
| Claude Mythos Preview | 107 → 25 | 38 → 17 | 12 → 3 |
| GPT-5.5 | 71 → 10 | 27 → 3 | 22 → 8 |
| GPT-5.4 | 38 → 2 | 15 → 0 | 1 → 1 |
| Claude Opus 4.6 | 12 → 0 | 2 → 0 | 1 → 0 |
図表3:防御機構の有効化前後のエクスプロイト成功数の変化(一部抜粋)
結果として、標準的な防御機構は依然として有効であり、大半のAIによる攻撃を無力化できることが分かりました。成功数は大幅に減少しています。
しかし、注目すべきは成功数が「ゼロにはなっていない」という点です。Claude Mythos PreviewやGPT-5.5は、メモリのランダム化を回避したり、既知の抜け道を利用してサンドボックスから脱出したりと、防御機構を自力で迂回して攻撃を成功させた事例が複数確認されました。現在の防御機構だけでは、AI主導の攻撃を完全に無力化するには不十分であることが示唆されています。
まとめ:自律的なサイバー攻撃への備え
ExploitGymを用いた検証により、自律的なエクスプロイト開発がもはや理論上の話ではなく、現実の脅威となりつつあることが明らかになりました。現時点では、AIがすべてのターゲットを確実に攻撃できるわけではありません。しかし、最先端のモデルはすでに複雑なシステムの脆弱性を突き、防御機構を突破する能力の片鱗を見せています。
AIの進化のスピードを考慮すると、現在のAIの限界を長期的な安全性の保証とみなすことはできません。企業や組織は、従来のセキュリティ対策がAIを利用した攻撃者に対して機能するかを再評価し、モデルの安全な開発と並行して、多層的な防御策を継続的に強化していく必要があります。
Webサービスや社内のセキュリティにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: