DevinやCopilotのセキュリティPR実態分析。人間がAIを拒む最大要因は「複雑さ」
公開日
GitHub上での開発において、DevinやGitHub Copilotといった「自律型コーディングエージェント(AIチームメイト)」がプルリクエスト(PR)を自動作成する事例が増加しています。これらAIエージェントは、機能実装だけでなく、脆弱性の修正やコードの堅牢化といったセキュリティ領域にも関与し始めていますが、その品質や人間の開発者による受け入れ状況については、これまで十分に明らかにされていませんでした。
本記事では、ノートルダム大学の研究チームらが発表した論文「Security in the Age of AI Teammates: An Empirical Study of Agentic Pull Requests on GitHub」に基づき、AIエージェントによるセキュリティ貢献の実態を解説します。
AIエージェントはセキュリティ開発にどれだけ貢献しているか
本調査では、5つの主要な自律型AIエージェント(OpenAI Codex, Cursor, Devin, Copilot, Claude Code)が実際のGitHubリポジトリで作成したPRを収録する「AIDevデータセット」を用いて、スター数が100以上の人気リポジトリから抽出された33,596件の精選されたデータを対象に、セキュリティ貢献の実態と人間の評価傾向を分析しました。
セキュリティPRの発生頻度とエージェント間の差
AIエージェントは、単なるコード補完ツールを超え、独立してタスクを遂行する存在となりつつあります。しかし、実際に彼らはどの程度セキュリティに関連するタスクを担っているのでしょうか。調査の結果、AIエージェントによる全活動のうち、セキュリティ関連の貢献は「意味のある割合」ではあるものの、全体から見ればまだ少数派であることが判明しました。
データセットを分析した結果、セキュリティに関連すると認定されたPRは1,293件であり、これは全体の約3.85%に相当します。この数字は一見低く見えますが、実数としては1,000件を超えており、無視できない規模でセキュリティ作業が自動化されつつあることを示しています。
特筆すべきは、使用するエージェントによってセキュリティタスクへの関与率が大きく異なる点です。以下の図表1は、主要なエージェントごとのセキュリティPRの割合を示しています。
 図表1:自律型コーディングエージェントごとのセキュリティ関連PRの普及率
図表1:自律型コーディングエージェントごとのセキュリティ関連PRの普及率
Claude Codeは全活動の14.6%がセキュリティ関連であり、最も高い割合を示しました。一方、OpenAI Codexは1.3%に留まっています。これは、エージェントの設計思想や、ユーザーがどのようなタスクを任せているかによって、セキュリティへの関与度が大きく変わることを示唆しています。
「信用ギャップ」の存在:人間による厳しい監視の目
AIエージェントがセキュリティコードを作成したとしても、それがそのまま採用されるわけではありません。一般的に、セキュリティ関連の修正は人間が作成したものであっても慎重にレビューされるため、時間がかかる傾向にあります。しかし、今回の調査データには、単なる「慎重さ」だけでは説明できない、AIエージェント特有の「信用ギャップ」が浮き彫りになりました。
通常タスクの迅速な処理とセキュリティタスクにおける大幅な遅延
まず注目すべきは、非セキュリティPRとセキュリティPRのレビュー時間の極端な差です。
以下の図表2に示す通り、セキュリティに関連しない通常のAI作成PRは、中央値わずか 0.11時間(約7分) でマージされています。これは、AIによるリファクタリングや軽微な修正に対して、人間がほぼ即座に承認を与えている状態を意味します。
一方で、セキュリティPRになると状況は一変し、中央値は3.92時間へと跳ね上がります。
| PRタイプ | PR総数 | 平均値 | 中央値 | 標準偏差 |
|---|---|---|---|---|
| セキュリティ | 1,130 | 97.45 | 3.92 | 239.91 |
| 非セキュリティ | 30,154 | 38.29 | 0.11 | 140.42 |
図表2:セキュリティPRと非セキュリティPRのマージ済みPRにおけるレビュー時間の比較(hour)
通常タスクではAIによる自動化の恩恵(スピード)を享受しているにもかかわらず、セキュリティ領域に入った途端、その約35倍もの時間をかけて検証を行っていることになります。この顕著な差異は、レビュアーが「AIのセキュリティコード」に対しては慎重な姿勢を崩さず、自動化のメリットが相殺されるほど入念な確認を行っていることを示唆しています。
エージェントごとの出力傾向による信頼度の違い
さらに興味深いのは、エージェントの種類によってレビュー時間の延び幅に大きなばらつきがある点です。以下の図表3は、各エージェントにおけるセキュリティPRと非セキュリティPRのレビュー時間(中央値)の差を示したものです。
| エージェント | セキュリティPR (h) | 非セキュリティPR (h) | 差分 (Delta) |
|---|---|---|---|
| Devin | 23.76 | 7.68 | +16.08 |
| Copilot | 18.32 | 12.87 | +5.46 |
| Claude Code | 5.13 | 1.71 | +3.42 |
| Cursor | 1.08 | 0.89 | +0.18 |
| OpenAI Codex | 0.07 | 0.02 | +0.05 |
図表3:エージェントごとのレビュー時間(中央値)の比較
表にある通り、Devinが作成したセキュリティPRは、非セキュリティPRに比べて約16時間も長くレビューされています。対照的に、OpenAI Codexの場合、その差はわずか数分(0.05時間)程度でした。
もしセキュリティタスクが一律に困難であるならば、どのAIを使用しても同様に時間がかかるはずです。しかし実際には、エージェントごとに生成されるPRの性質や品質傾向が異なるため、レビュー時間には明確な差が生まれています。
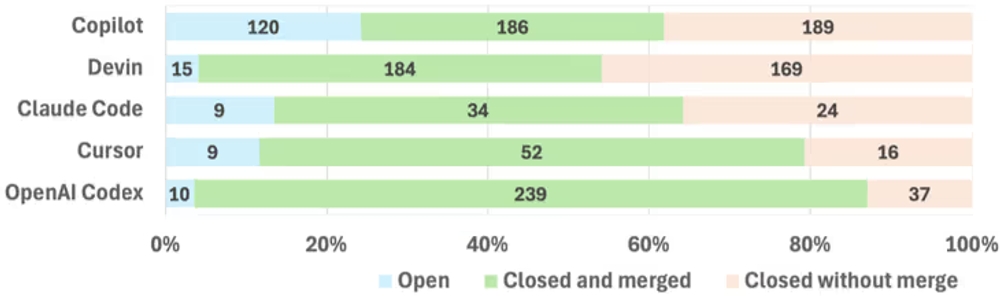
 図表4:エージェントごとのセキュリティ関連PRの結果(マージ済み、クローズ済み等)
図表4:エージェントごとのセキュリティ関連PRの結果(マージ済み、クローズ済み等)
図表4のマージ率を見ても、OpenAI Codexは86.59%と高い数値を示していますが、Copilotは49.60%と苦戦しています。これは、Copilotが脆弱性修正のような高リスクなタスクを多く任されている傾向があることや、各エージェントが生成するコードの品質差が、結果としてレビュアーの検証時間に影響を与えていると考えられます。つまり、レビュアーはエージェントの名前で判断しているのではなく、各エージェントが生み出す成果物の傾向に合わせて、無意識的に検証の深度を変えている可能性があります。
AIは何を「セキュリティ対応」として行っているのか
「セキュリティ対応」と一口に言っても、その内容は多岐にわたります。AIエージェントは具体的にどのようなコード変更を行っているのでしょうか。定性的な分析から、AIは単に既知の脆弱性を塞ぐだけでなく、より広範な「品質向上」の一環としてセキュリティを捉えていることが分かりました。
修正内容(アクション)と意図(インテント)の分析
研究チームは、セキュリティPRの内容を「修正内容(アクション)」と「意図(インテント)」に分類しました。その結果、AIエージェントは「コードのリファクタリング」「テストの追加」「ドキュメントの整備」といった、予防的な堅牢化作業を頻繁に行っていることが判明しました。
修正内容(アクション)上位5件
| テーマ | 件数 |
|---|---|
| コードリファクタリング | 957 |
| テスト | 755 |
| ドキュメント | 692 |
| エラーハンドリング | 595 |
| セキュリティ改善 | 580 |
意図(インテント)上位5件
| テーマ | 件数 |
|---|---|
| 機能性の向上 | 890 |
| 脆弱性の軽減 | 741 |
| ユーザー体験 | 697 |
| エラーハンドリング | 604 |
| セキュリティ強化 | 531 |
図表5:オープンコーディングにより特定されたセキュリティアクションとインテント(抜粋)
この表から読み取れる重要な点は以下の通りです。
- アクション(実装内容): 「コードリファクタリング」が957件と最多であり、次いで「テスト」「ドキュメント」が続きます。これは、AIがセキュリティを「機能の一部」として組み込んで処理していることを示唆しています。
- インテント(動機): 「機能性の向上」が890件でトップであり、「脆弱性の軽減」の741件を上回りました。
つまり、AIエージェントによるセキュリティ作業は、狭義の「セキュリティ修正」だけでなく、ユーザビリティや保守性の向上を含めた、より包括的なソフトウェアエンジニアリング活動として行われているのです。
どのようなセキュリティPRが却下されるのか
最後に、AIが作成したセキュリティPRが「マージされずに却下される(クローズされる)」要因について分析します。PR作成時の初期情報から、どのような特徴が却下につながるのでしょうか。
却下を予測する最大の要因は「複雑さ」
分析の結果、PRのタイトルに「認証(auth)」「暗号(crypto)」といったセキュリティ用語が含まれているかどうかは、クローズ率にほとんど影響しないことが分かりました。むしろ、PRが却下される最大の要因は、変更内容の「複雑さ」と「説明の冗長さ」にありました。
以下の図表6は、PRの特徴と却下の関連性(ロジスティック回帰係数)を示しています。
| 特徴量 | 係数 (β) |
|---|---|
| タイトルの長さ | 0.316 |
| PRのサイズ | 0.049 |
| 説明文の長さ | 0.049 |
| タイトル内のセキュリティ用語 | -0.054 |
| AIエージェント名 | -0.268 |
図表6:キュレーションされたセキュリティPRデータセットにおける初期シグナルとPR却下の関連
- タイトルの長さ: 係数が0.316と最も高く、タイトルが長いほど却下されやすい傾向があります。
- PRのサイズと説明文の長さ: これらも正の相関を示しており、変更行数が多く、説明が長くなるほど、レビュアーにとっての認知負荷が高まり、却下されるリスクが増加します。
逆に、セキュリティ用語の有無は係数が負(-0.054)となっており、セキュリティに関する話題であること自体は、却下の直接的な原因ではないことが示唆されています。つまり、レビュアーは「何についての変更か」よりも、「変更が簡潔で理解しやすいか」を重視して判断を下していると言えます。
結論
本研究の結果は、自律型AIエージェントがすでに実世界のソフトウェア開発において、セキュリティタスクの一翼を担っていることを示しています。しかし、その貢献は人間のレビュアーによって厳格に精査されており、特に複雑で大規模な変更は却下されやすい傾向にあります。
AIエージェントをセキュリティ開発に効果的に組み込むためには、以下の点が重要になります。
- 変更のスコープを絞る: 巨大な修正を一度に行うのではなく、焦点を絞った小さな変更を行うほうが、人間の信頼を得やすくマージされやすい。
- 予防的な堅牢化の活用: AIは脆弱性修正だけでなく、テスト追加やリファクタリングなどの「守りの強化」においても有用である。
- 人間との協調: レビュアーの負荷を考慮し、AI側が分かりやすい説明や根拠を提示できるような設計が求められる。
AIは強力なチームメイトになり得ますが、セキュリティという極めてセンシティブな領域においては、人間による監督と、AI側の「人間に理解されやすい振る舞い」の双方が不可欠です。