30万件のデータから判明したAIサプライチェーンの課題:開発現場の実態と対策
公開日
急速なAIモデルやアプリケーションの普及に伴い、開発者は従来のソフトウェアにはない新たなセキュリティ上の脅威に直面しています。しかし、理論的なリスクフレームワークと、実際に現場の開発者が遭遇している問題との間には、大きなギャップが存在するのが現状です。
本記事では、アデレード大学およびElevexai Systemsの研究チームが執筆し、ソフトウェア工学の国際会議ICSE 2026で発表予定の論文「Securing the AI Supply Chain: What Can We Learn From Developer-Reported Security Issues and Solutions of AI Projects?」に基づき、AIサプライチェーンにおけるセキュリティの実態を解説します。
AIセキュリティ報告の急激な増加と現状
研究チームは、Hugging FaceとGitHub上の開発者による議論データを収集し、独自に調整したAIモデル(distilBERT)を用いてセキュリティに関連する投稿を抽出しました。その結果、312,868件ものセキュリティ関連の議論が特定されました。
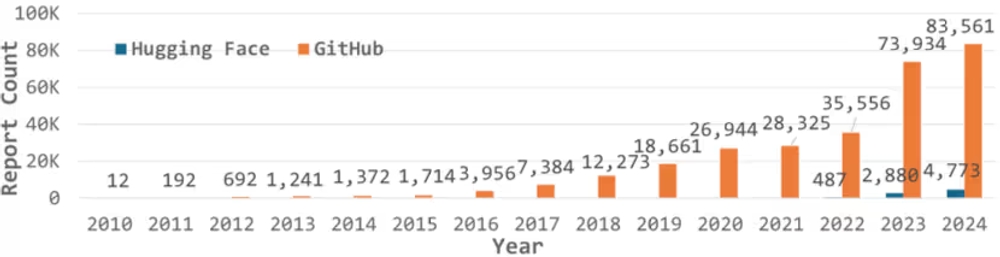
まず注目すべきは、AIプロジェクトに関するセキュリティ報告の急激な増加です。特に2023年から2024年にかけて、コミュニティ内での議論数は指数関数的に伸びています。これは、ChatGPTの登場以降、生成AI技術が急速に普及した時期と重なります。
 図表1:AIセキュリティ報告数の経年変化
図表1:AIセキュリティ報告数の経年変化
一方で、これらの議論のうち、公式な脆弱性データベース(CVE)に登録されているものは0.1%未満に過ぎませんでした。これは、公的な脆弱性管理プロセスが、現場で発生しているAIセキュリティの問題のスピードと量に追いついていないことを示唆しています。開発者は公式な修正を待つよりも、コミュニティ内での議論を通じて独自に解決策を模索しているのです。
開発者が直面する4つのセキュリティ領域
研究チームは、収集したデータから抽出した753件の投稿を詳細に分析し、AIプロジェクトにおけるセキュリティ問題を以下の4つのテーマに分類しました。
- システムとソフトウェア: 従来のソフトウェア開発と同様のコード実行やランタイムの互換性問題。
- 外部ツールとエコシステム: サードパーティ製の依存関係やプラットフォームの認証などに関する問題。
- モデル: AIモデルの入出力、プロンプトインジェクション、モデルの盗用など、AI固有の問題。
- データ: 学習データの漏洩、データの完全性(ポイズニングなど)に関する問題。
以下の表は、それぞれの領域で具体的にどのような課題が議論されているかを示したものです。
| テーマ | 課題サブテーマ | コード数 | 頻度 | カバー率 |
|---|---|---|---|---|
| システムとソフトウェア | システムランタイムの互換性問題 | 3 | 325 | 34.53% |
| コード実行セキュリティ問題 | 7 | 229 | 22.58% | |
| デプロイとインフラのセキュリティ問題 | 3 | 182 | 21.65% | |
| メモリとリソースのセキュリティ問題 | 2 | 162 | 17.93% | |
| 安全な通信に関する問題 | 2 | 47 | 6.24% | |
| 外部ツールとエコシステム | 依存関係のセキュリティ問題 | 3 | 201 | 24.04% |
| 外部サービス利用のセキュリティ問題 | 3 | 138 | 16.87% | |
| モデル | モデル出力とコンテンツ制御の問題 | 3 | 101 | 10.76% |
| モデル入力とプロンプトセキュリティの問題 | 2 | 63 | 7.57% | |
| データ | データ漏洩問題 | 2 | 48 | 5.98% |
| データ完全性問題 | 2 | 29 | 3.72% |
図表2:課題のサブテーマ一覧と発生頻度
この分類から、依然として「システムとソフトウェア」に関する議論が最も多く、全体の大部分を占めていることがわかります。しかし、AI開発においては「モデル」や「データ」といった新しい領域のリスク管理が不可欠になっています。
解決策が不足している「モデル」と「データ」の領域
今回の調査で最も浮き彫りになった課題は、 「システムやツールに関する問題には解決策が存在するが、モデルやデータに関する問題には有効な解決策がほとんど提示されていない」 という点です。
以下のヒートマップは、各セキュリティ問題に対して、どの程度の解決策が提示されているかを可視化したものです。
 図表3:課題と解決策の分布ヒートマップ
図表3:課題と解決策の分布ヒートマップ
図表3を見ると、「システムとソフトウェア」の領域(左上)には多くの解決策が分布していますが、「モデル」や「データ」の領域(右側)は空白が目立ちます。
例えば、プロンプトインジェクション(悪意ある入力によってモデルの挙動を操作する攻撃)については多くの報告がありますが、提示されている解決策は「プロンプトテンプレートの変更」や「出力のフィルタリング」といった一時的な対処療法に留まっています。根本的な防御策は確立されておらず、開発者は試行錯誤を強いられています。同様に、データの漏洩や汚染に関しても、具体的な技術的解決策よりも「データ使用の停止」や「注意喚起」といった運用回避策が多く見られました。
現場で多発する具体的な脆弱性
議論の中で頻繁に登場した具体的な脆弱性についても触れておきます。
安全でないデシリアライズ(pickle問題)
Pythonのデータ保存形式である「pickle」に関する問題は、Hugging FaceとGitHubの両方で頻繁に報告されています。pickleファイルは読み込み時に任意のコードを実行できる仕様となっているため、悪意のあるモデルファイルを読み込むだけでシステムが乗っ取られるリスクがあります。開発者の間では、より安全な形式である「safetensors」への移行が推奨されていますが、依然として多くのプロジェクトでpickleが使用されています。
依存関係の複雑さ
AIプロジェクトは、PyTorchやTensorFlowといった巨大なフレームワークだけでなく、多数のサードパーティ製ライブラリに依存しています。調査では、依存ライブラリのバージョン不整合によるクラッシュや、悪意のあるパッケージが混入するサプライチェーン攻撃のリスクについて多くの議論が確認されました。これに対し、開発者は依存関係の固定(ピンニング)や、スキャンツールの導入で対抗しようとしています。
結論
本調査により、AIサプライチェーンのセキュリティリスクは、従来のソフトウェア脆弱性と、AI固有のブラックボックスな要素(モデル・データ)が複雑に絡み合っていることが明らかになりました。
特に懸念されるのは、モデルやデータに関するセキュリティ対策が、現場レベルではまだ確立されていないことです。研究チームは、今後の対策として、モデルのアーキテクチャや学習データの詳細、既知の脆弱性を記録した AIBOM(AI Software Bill of Materials:AIソフトウェア部品表) の導入と標準化を提言しています。
開発者は、既存のセキュリティツールを活用しつつも、AIモデルやデータが抱える固有のリスクに対しては、常に最新のコミュニティ情報を注視し、慎重に扱う必要があります。今回の研究結果は、AIセキュリティがまだ発展途上の段階にあり、継続的な警戒と技術開発が必要であることを示しています。
Webサービスや社内のセキュリティにお困りですか? 弊社のサービス は、開発チームが抱える課題を解決し、生産性と幸福度を向上させるための様々なソリューションを提供しています。ぜひお気軽にご相談ください!
参考資料: